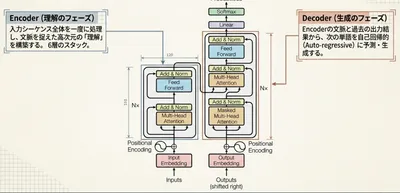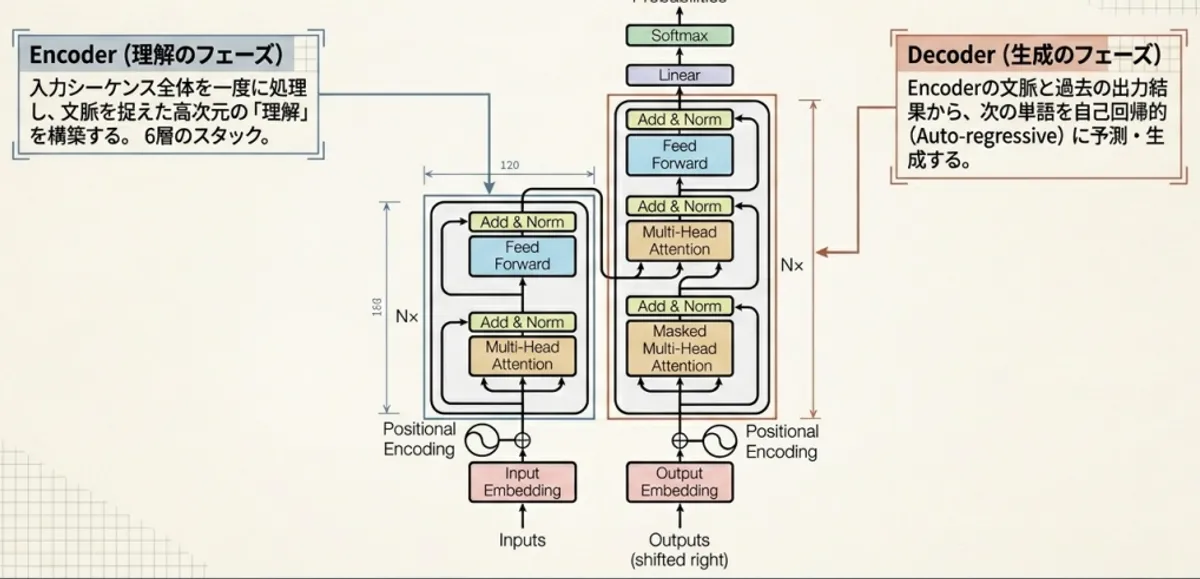
1. Transformerとは?──なぜ生まれたか
2017年、Googleの研究者たちが「Attention Is All You Need」という論文を発表し、Transformerが誕生しました。
それ以前、自然言語処理(NLP)の主役はRNNとそれをベースにしたエンコーダ-デコーダモデルでした。 しかしRNNには、根本的な欠点がありました。
逐次処理しかできない。 単語を1つずつ順番に処理するため、
- 文が長いほど訓練が遅くなる(GPUの並列計算をほとんど使えない)
- 先頭付近の情報が薄れていく長距離依存問題が生じる
たとえば100単語の文で先頭の主語を参照しようとすると、RNNは100ステップ分の情報を引き継がなければなりません。
そこでTransformerは再帰も畳み込みも使わず、Attentionだけで系列変換を行うという大胆な設計を採用しました。 これにより入力を一度に並列処理でき、学習速度と精度が飛躍的に向上しました。
結果として翻訳タスクで当時の最高精度(BLEU 28.4)を大幅に更新しただけでなく、 BERT・GPT・T5・ViTなど現代のほぼすべての大型モデルの基盤となっています。
Transformerを理解することは、現代AIの基礎を理解することに等しいのです。
2. 全体アーキテクチャ──大きな流れを掴む
TransformerはEncoder-Decoder構造を採用しています。 まず全体の流れを掴んでから、各モジュールを詳しく見ていきましょう。
ここでは「Yo tengo gatos(スペイン語)→ I have cats(英語)」の翻訳を例にとります。
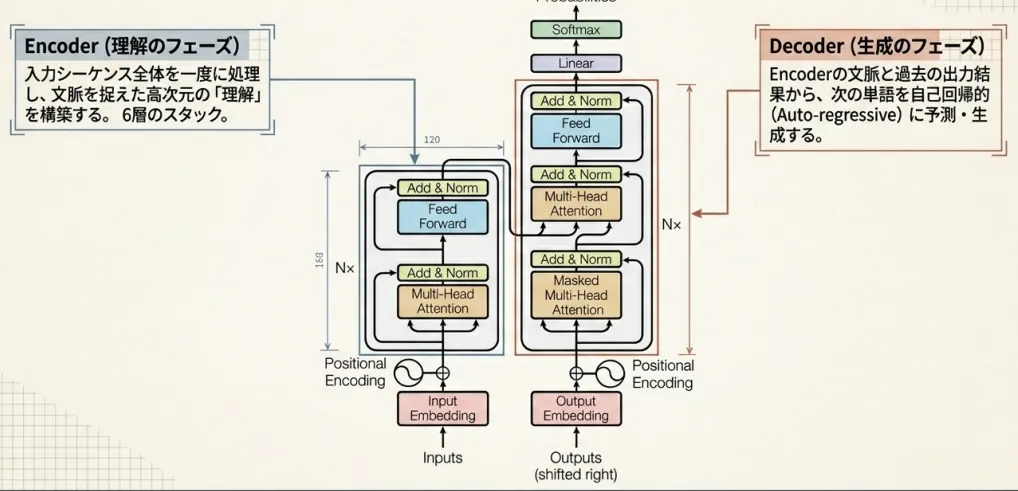
- Encoder:原文を受け取り、「文脈を考慮した単語ベクトル」に変換する
- Decoder:Encoderの出力を参照しながら、翻訳文を1単語ずつ生成する
各ブロックが6層重なっており、層を通るほど抽象度の高い表現になっていきます。 では、入力の前処理から順に中身を見ていきましょう。
3. 入力の準備──単語をベクトルに変換する
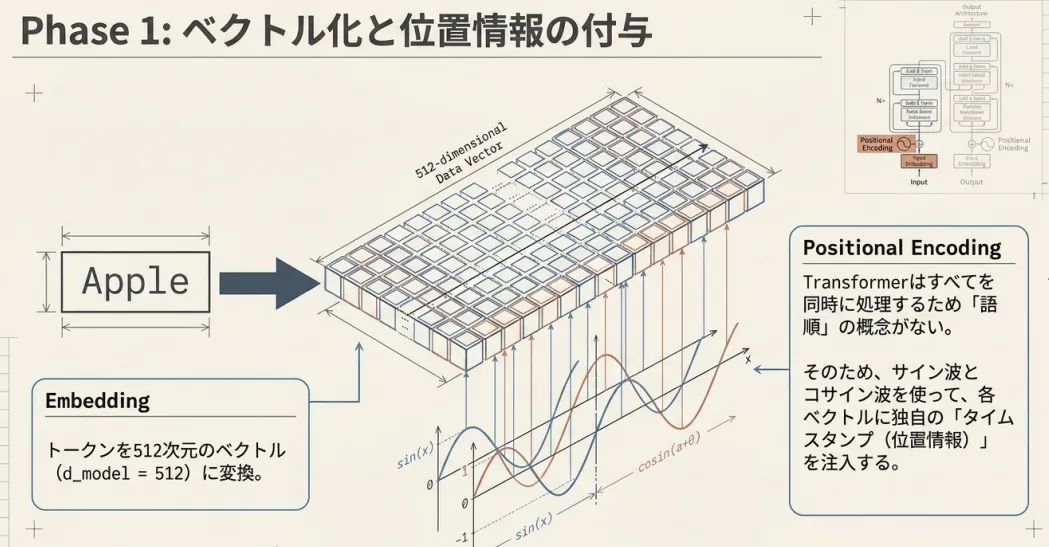
3.1 単語埋め込み(Word Embedding)
ニューラルネットが扱えるのは数値だけです。
まず「単語」という離散的な記号を、数値のベクトルに変換する必要があります。
最もシンプルな方法は、語彙数分の次元を用意してその単語だけ1にするone-hotエンコーディングです。 しかしこれでは「cat」と「dog」の距離も「cat」と「Tokyo」の距離も同じになってしまい、単語間の意味的な近さが表現できません。
そこで使われるのが単語埋め込みです。
各単語を次元の実数ベクトルにマッピングします。
訓練を通じて似た文脈で登場する単語には似たベクトルが割り当てられるようになります。 つまり、ベクトルの差や和が意味的な関係を反映します。 "512次元のベクトル"は、各単語が持つ意味・品詞・使われ方などの情報を、512個の実数で圧縮して表現したものです。
この単語埋め込みの重み行列は、 訓練を通じて学習されます(は語彙サイズ)。
3.2 位置エンコーディング(Positional Encoding)
ここで問題があります。Attentionは単語を「集合」として扱うため、単語の順序を考慮しません。 "I love cats" と "cats love I" が区別できず、同じ入力として扱われてしまいます。
これを解決するため、各単語ベクトルに位置情報のベクトル(Positional Encoding)を加算します。
位置エンコーディングの計算式
変数の意味を確認しましょう。
- :文中の位置。最初の単語が0、次が1、…と続く
- :512次元のうち何番目の次元か(0〜255)
- :ベクトルの次元数(= 512)
ポイントは次元ごとに異なる周期のsin/cos波を割り当てることです。 が大きくなるほど分母が大きくなり、波の周期が長くなります。
i = 0 → 周期が非常に短い波(隣の位置で大きく変化)i = 128 → 周期が非常に長い波(隣の位置ではほとんど変化しない)これは時計のアナログ表示に似ています。 秒針(i = 0)は1分で一周する短い周期、 分針(i = 1)は60分で一周する長い周期—— 複数の針を組み合わせることで、どの時刻かを一意に特定できます。 位置エンコーディングも同じ発想で、短い周期から長い周期まで複数の波を重ねることで、各位置に一意なベクトルを生成します。
sin/cosには重要な数学的性質があります。 任意の相対位置に対して、 がの線形変換で表せます。
これは三角関数の和積の公式から導かれます。
、とおくと、 PE(pos+k)の各次元はPE(pos)の対応する2次元(sinとcos)の線形結合になっています。
このおかげで、Attentionが「2単語間の距離」を学習しやすくなります。 また、sinとcosの値域は常にに収まるため、 訓練時より長い文章が来ても値が爆発せず、外挿(未見の長さへの適用)も可能です。
最終的に、単語埋め込みと位置エンコーディングを足し合わせたベクトルが Encoderへの入力として使われます。
4. Encoder──文脈を考慮した表現を作る
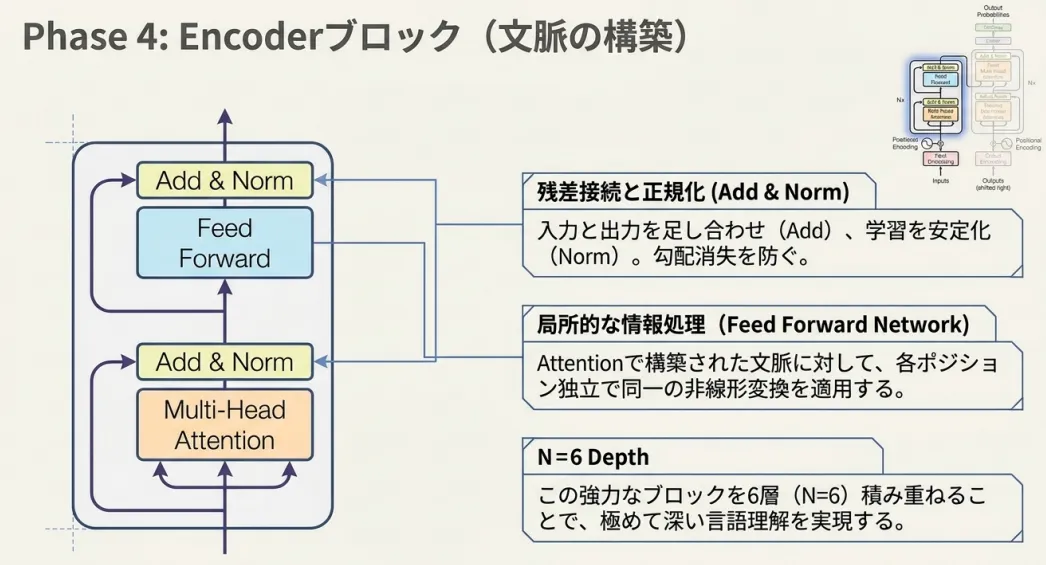
Encoderブロックは以下の3つのコンポーネントで構成されています。
- Multi-Head Self-Attention
- Position-wise Feed-Forward Network
- 残差接続(Add)& Layer Normalization(Norm)
順番に見ていきましょう。
4.1 Attentionメカニズム──単語間の「関連度」を計算する
Attentionの動機から始めます。
The animal didn't cross the street because it was too tired.
この文で"it"が何を指すか理解するには、"animal"に注目する必要があります。 RNNはこれを「情報を順番に引き継ぐ」ことで解決しようとしましたが、 文が長いと情報が薄れてしまいます。
Attentionは発想を変えます。すべての単語ペアの関連度を一度に計算してしまおうという考え方です。
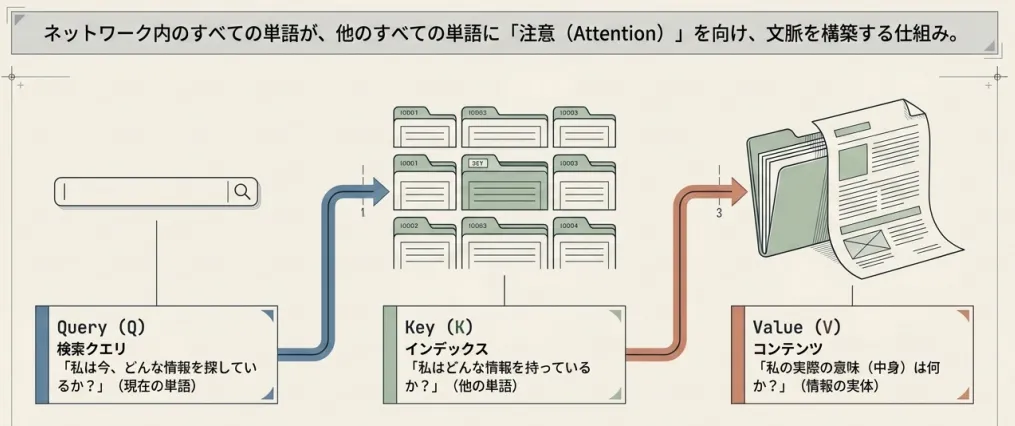
Query・Key・Value(Q・K・V)
AttentionはQuery(Q)・Key(K)・Value(V)という3種類のベクトルで計算されます。 まず「なぜ3種類も必要なのか」という動機から始めましょう。
素朴なAttentionの問題点
最もシンプルな「単語間の関連度」の測り方は、 単語ベクトル同士の内積をそのまま使うことです。
しかしこれでは、「関連度の計算に使う側面」と「実際に渡す情報」が同じベクトルになってしまいます。
「"it"が何を指すか調べたい」(検索の目的)という側面と、「"it"という単語そのものが持つ情報」(渡す内容)は、本来別々に最適化されるべきです。
そこでQ・K・Vを分離します。
Query(Q):「私は何を探しているか」── 検索する側の表現
Key(K):「私はどんな情報を持っているか」── 検索される側の表現
Value(V):「実際に渡す情報の中身」── 検索がヒットしたときに渡すデータ
Q・K・Vの生成
入力埋め込み行列(は単語数)に対して、 学習可能な重み行列をかけることでQ・K・Vを生成します。
ここで各重み行列の形はです()。
この線形変換が重要な意味を持ちます。 同じ入力ベクトル("it"のベクトル)から出発しても、
- をかけると「itが何かを探すときの表現」に変換される
- をかけると「itが検索されたときにヒットしやすい表現」に変換される
- をかけると「itが実際に渡す情報の表現」に変換される
3つの重み行列が「同じ単語の3つの異なる役割」を学習するというわけです。
"I have cats"(3単語)の場合、行列の形を追うと:
X : (3, 512) ← 3単語 × 512次元W^Q : (512, 64)W^K : (512, 64)W^V : (512, 64)─────────────────────────────Q = XW^Q : (3, 64) ← 3単語分のQueryベクトルK = XW^K : (3, 64) ← 3単語分のKeyベクトルV = XW^V : (3, 64) ← 3単語分のValueベクトルScaled Dot-Product Attention
Q・K・VからAttentionを計算する式は以下のとおりです。
行列の形を追いながら、4ステップで読み解きましょう。
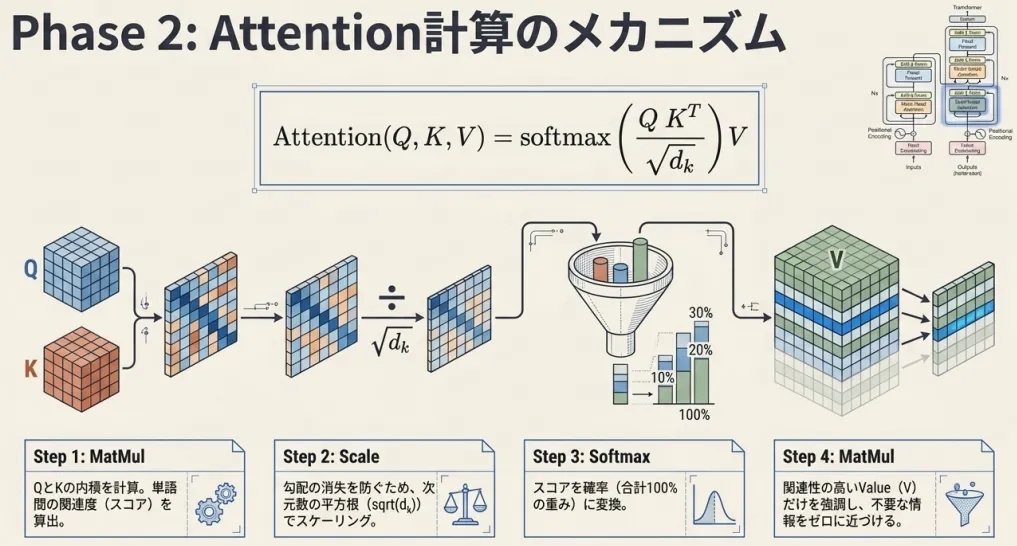
Step 1:スコア行列の計算
Q : (3, 64)K^T: (64, 3)──────────────S : (3, 3) ← 全単語ペアのスコアが一度に得られるは「単語が単語にどれだけ関連しているか」を表すスコアです。 "I have cats" なら:
I have catsI [ 24.1, 3.2, 0.8 ]have [ 2.1, 22.4, 3.8 ]cats [ 0.9, 4.1, 23.7 ](値は説明のためのイメージです)
Step 2:スケーリング
次元の内積は、次元数が大きいほど値が大きくなる傾向があります。 (各次元の寄与が足し合わされるため)
値が大きすぎるとsoftmaxへの入力が極端になり、出力が「0か1か」のような分布に飽和します。 すると勾配がほぼ0になり、学習が止まってしまいます。
で割ることで値のスケールを揃えます。直感的には「内積の期待値の標準偏差で割る」操作です。
Step 3:Softmaxで注意重みへ変換
各行に対してsoftmaxを適用します。これにより各行の和が1になり、「確率分布」として解釈できます。
I have catsI [ 0.88, 0.10, 0.02 ] ← "I" はほぼ自分自身に注目have [ 0.08, 0.80, 0.12 ] ← "have" は自分と "cats" に注目cats [ 0.03, 0.14, 0.83 ] ← "cats" はほぼ自分自身に注目この行列がAttention重み(Attention Map)です。 各行が「その単語がどの単語にどれだけ注目しているか」を表します。
Step 4:Valueの加重和
A : (3, 3)V : (3, 64)────────────────Output : (3, 64) ← 各単語の「文脈を考慮した新しい表現」たとえば "have" の出力ベクトルは:
Output["have"] = 0.08 × V["I"] + 0.80 × V["have"] + 0.12 × V["cats"]"have" は自分自身のValueを80%、"cats"のValueを12%取り込んだ表現になります。 **「"have"の意味は"cats"との関係によって少し変わる」**という文脈情報が、この加重和に埋め込まれているわけです。
Multi-Head Attention
前節のScaled Dot-Product Attentionは1組ので計算します。 これはつまり、Attentionの重み行列がひとつの視点でしか表現できないことを意味します。
しかし、自然言語の単語間には、同時に複数の関係が存在します。
"The animal didn't cross the street because it was too tired."
"it"と他の単語の間には、少なくとも以下の関係が同時に存在します。
- 照応関係:it → animal (照応先)
- 構文関係:it → was (主語-述語)
- 意味関係:it → tired (状態の主体)
1ヘッドでは、これら全てを1枚のAttentionマップに押し込めなければならず、 どれかの関係が犠牲になります。
Multi-Headの仕組み
解決策は単純です。 Attention計算を個並列に走らせ、それぞれ独立したQ・K・Vを持たせることです。
論文ではヘッドを使用します。 ここで重要な工夫があります。各ヘッドの次元を縮小して合計の計算コストを保ちます。
1ヘッドを512次元で動かす代わりに、64次元のヘッドを8個並列に走らせます。 計算量はほぼ同じでありながら、8つの独立した視点が得られます。
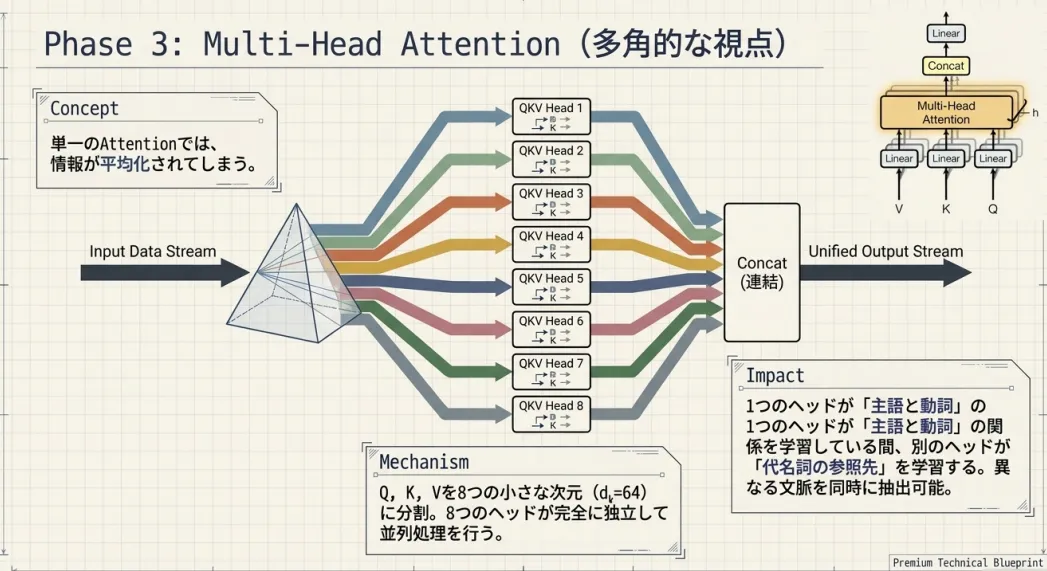
各ヘッドの計算:
ここでは、 ヘッドごとに独立した重み行列です。同じ入力から出発しても、 異なる重み行列をかけることで「異なる側面を切り出す射影」が学習されます。
Concatと射影
8つのヘッドの出力を次元方向に結合(Concat)します。
ここで512次元に戻りましたが、これは単なる「くっつけた」状態です。 ヘッド間の情報を混合するために、重み行列をかけて射影します。
の役割は「8つのヘッドが独立して学習した情報を、 うまく混ぜ合わせて統合する」ことです。 最終的な出力は入力と同じの形になり、次の層へと渡されます。
論文の著者らが学習済みモデルのAttentionマップを可視化したところ、 ヘッドごとに明確に異なるパターンが現れました。
- あるヘッドは照応関係("it" → "animal")に強く反応
- あるヘッドは構文的な隣接関係に集中
- あるヘッドは文末の区切り記号に注目
これは設計で強制したわけでなく、訓練を通じて自然に分化したものです。
4.2 Position-wise Feed-Forward Network
なぜAttentionの後にFFNが必要か
Multi-Head Attentionの出力は「どの単語の情報をどれだけ混ぜるか」を計算したものです。 しかしこの操作は本質的に線形です(加重和にすぎません)。
線形変換をいくら積み重ねても、表現できる関数のクラスは変わりません。 深いネットワークの恩恵を受けるには、非線形変換を挟む必要があります。
また、Attentionは「単語間の情報のやり取り」に特化しています。 Attentionで得た「文脈を取り込んだ表現」を、さらに各単語の内部で変換・整理する層が必要です。 これがFFNの役割です。
FFNの計算
2層の全結合層で、はReLU活性化関数です。
重み行列は全単語で共有されますが、 適用は完全に独立です。Attentionが「単語間の情報交換」なら、 FFNは「各単語内での情報整理」と理解できます。
4.3 残差接続(Add)& Layer Normalization(Norm)
残差接続(Add)──「変化分だけ学習する」
6層のブロックを積み重ねると、勾配消失が深刻な問題になります。 誤差逆伝播では、勾配が層を遡るたびに掛け算されるため、 深い層ほど勾配が指数的に小さくなります(1未満の数を何度もかけるため)。
残差接続はこれを次の式で解決します。
通常のネットワークがを学習するのに対し、 残差接続ではが「入力からの変化分」を学習します。
重要な性質として、逆伝播の際に勾配がのパスを通って そのまま(掛け算なしで)前の層まで届きます。 どれだけ層が深くても勾配が消えにくくなり、6層のブロックが安定して訓練できます。
Layer Normalization(Norm)──「スケールを揃える」
学習が進むにつれて、各層の出力の分布がずれていく「内部共変量シフト」が起きます。 これにより学習が不安定になったり、収束が遅くなったりします。
Layer Normalizationはこれを防ぐため、各サンプルの全特徴量次元にわたって正規化を行います。
- :そのサンプルの512次元にわたる平均・標準偏差
- :スケールとシフトの学習パラメータ
- :ゼロ除算防止の小さな定数
5. Decoder──翻訳文を1単語ずつ生成する
DecoderはEncoderと同様のブロック(Self-Attention → FFN → Add&Norm)を持ちますが、 2つの重要な追加要素があります。まず全体像を確認しましょう。
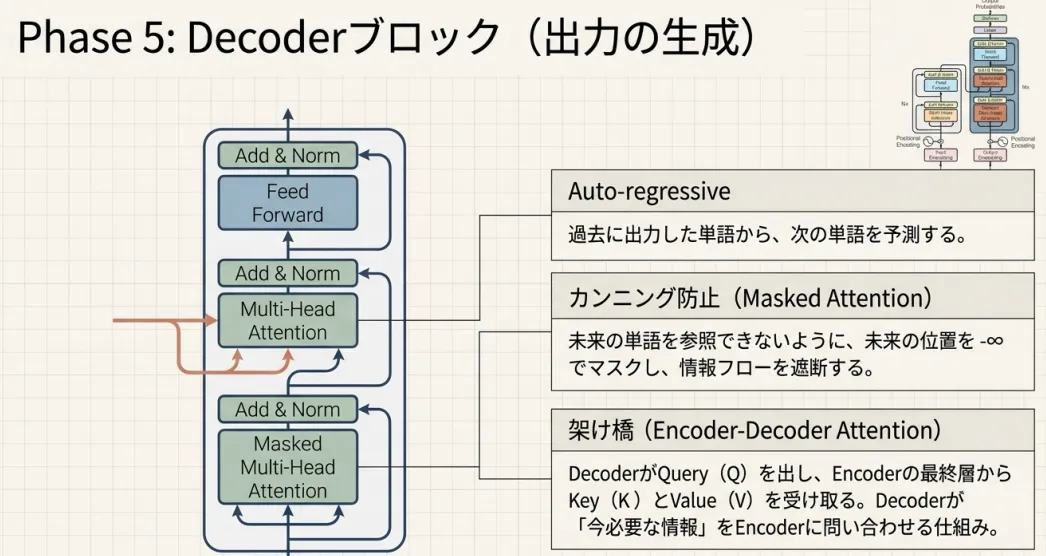
推論時のDecoderの動作は次のとおりです。
Step1: <start> → "I"Step2: <start> → "I" → "have"Step3: <start> → "I" → "have" → "cats"Step4: <start> → "I" → "have" → "cats" → <end>1単語ずつ生成し、生成した単語を次のステップの入力に加えながら繰り返します。 この自己回帰的な生成は直感的ですが、訓練時には問題があります。
5.1 Masked Multi-Head Self-Attention
訓練時の工夫:Teacher Forcing
推論時と同じように「1単語ずつ生成→次の入力に追加」を繰り返すと、 訓練が非常に遅くなります。誤った単語を生成するたびにその後の計算が全て狂うためです。
そこで訓練時はTeacher Forcingという手法を使います。 「モデルが生成した単語」ではなく、正解の翻訳文をまとめてDecoderに渡し、 全ての位置を並列に予測させます。
Encoder入力 : "Yo tengo gatos"Decoder入力 : <start>, "I", "have", "cats" ← 正解をまとめて渡すDecoder出力 : "I", "have", "cats", <end> ← 全位置を一度に予測しかしこれには問題があります。 "have"を予測するときに正解の"cats"が見えてしまいます。これはカンニングです。
マスキングの仕組み
これを防ぐのがマスキングです。 スコア行列を計算した後、 「現在の位置より右」の要素をに置き換えます。
"I have cats"(4トークン)のスコア行列の変化を追いましょう。
マスク適用前:
<start> I have cats<start> [ 3.2, 1.1, 0.8, 2.4 ]I [ 2.1, 4.5, 1.3, 0.9 ]have [ 0.8, 2.3, 3.7, 1.2 ]cats [ 1.4, 0.6, 2.1, 4.8 ]マスク適用後(右上をに):
<start> I have cats<start> [ 3.2, -∞, -∞, -∞ ]I [ 2.1, 4.5, -∞, -∞ ]have [ 0.8, 2.3, 3.7, -∞ ]cats [ 1.4, 0.6, 2.1, 4.8 ]Softmaxを適用するとの部分はになるため、 未来の単語へのAttention重みが完全に0になります。
softmax後:<start> I have cats<start> [ 1.00, 0.00, 0.00, 0.00 ] ← <start>しか参照できないI [ 0.19, 0.81, 0.00, 0.00 ] ← <start>とIだけ参照have [ 0.08, 0.32, 0.60, 0.00 ] ← haveまで参照cats [ 0.05, 0.07, 0.20, 0.68 ] ← 全て参照可これにより訓練時でも「未来の単語は見えない」という推論時と同じ制約が実現され、 かつ全位置を並列に計算できます。
5.2 Cross-Attention──EncoderとDecoderをつなぐ
なぜCross-Attentionが必要か
Masked Self-Attentionが終わった段階で、Decoderは 「これまでに生成した訳語の文脈表現」を持っています。 しかしこれだけでは、原文のどの部分に対応する翻訳を生成すべきかがわかりません。
Cross-Attention(Encoder-Decoder Attention)がその橋渡しをします。
Q・K・Vの出所
- Query(Q):Decoderの前層出力(「今、何を生成しようとしているか」)
- Key(K):Encoderの最終出力(「原文の各単語がどんな内容を持っているか」)
- Value(V):Encoderの最終出力(「原文の各単語から実際に取り出す情報」)
QだけDecoderから、K・VはEncoderから来ます。 Self-Attentionとの違いはここです。
行列の形で確認しましょう。"Yo tengo gatos"(3単語)→ "I have cats"(3単語)の例:
Encoder最終出力 : (3, 512) ← "Yo", "tengo", "gatos" の文脈表現Decoder前層出力 : (3, 512) ← "I", "have", "cats" の途中表現Q = Decoder × W^Q : (3, 64) ← 「何を生成しようとしているか」K = Encoder × W^K : (3, 64) ← 「原文の各単語のキー」V = Encoder × W^V : (3, 64) ← 「原文の各単語の内容」Attention(Q, K, V) : (3, 64) ← 「各訳語が原文のどこを参照したか」Attentionスコア行列のイメージ:
Yo tengo gatosI [ 0.85, 0.10, 0.05 ] ← "I"は"Yo"を強く参照have [ 0.07, 0.88, 0.05 ] ← "have"は"tengo"を強く参照cats [ 0.04, 0.08, 0.88 ] ← "cats"は"gatos"を強く参照「cats」を生成しようとするDecoderのQueryが、 Encoderの「gatos」のKeyと強く一致することで、 「gatos」のValueから情報を多く引き出す——これが翻訳のアライメントです。
なおCross-AttentionにはMaskはありません。 訳語を生成するとき、原文全体を参照するのは正当だからです。
EncoderとDecoderのデータフロー(まとめ)
原文: "Yo tengo gatos"↓ ↓ ↓[Encoder × 6層]↓ ↓ ↓Encoder出力: (3, 512) ──────────────────────┐↓(K, Vとして)訳文: <start>, "I", "have" [Cross-Attention]↓ ↓ ↓ ↑(Qとして)[Masked Self-Attention] │↓ ↓ ↓ ───────────────────┘[Decoder × 6層]↓ ↓ ↓"I", "have", "cats"5.3 最終出力
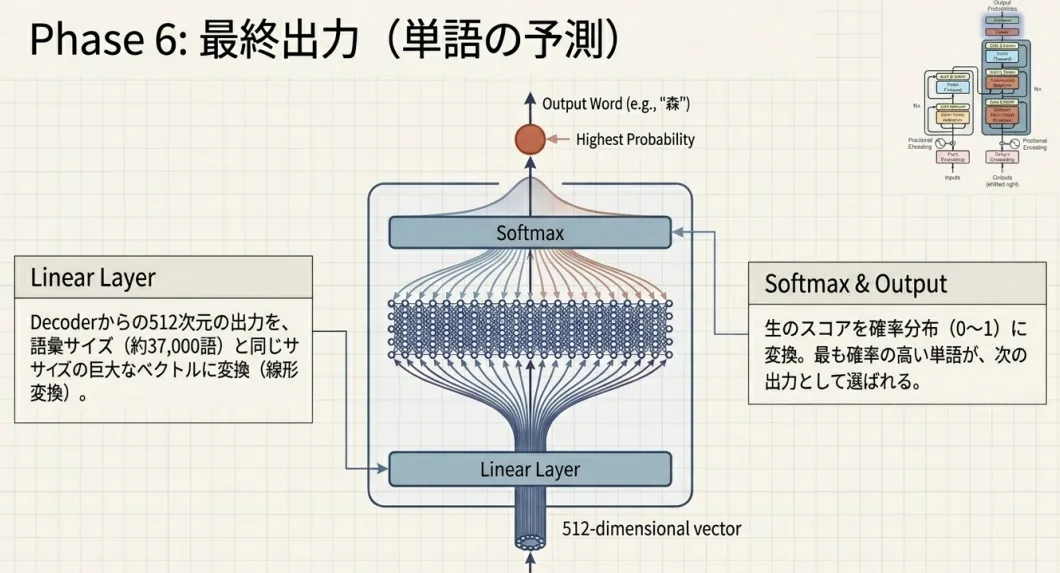
Decoderの最終層の出力を、 Linear層で語彙サイズに射影しSoftmaxで確率分布に変換します。
Decoder最終出力 : (1, 512) ← 1時刻分× W_out : (512, |V|) ← |V| = 語彙サイズ(約37,000)─────────────────────────────ロジット : (1, 37000)softmax後 : (1, 37000) ← 各単語の確率確率が最も高い単語をその時刻の出力とし(greedy decoding)、 が出るまで繰り返します。
出力層の重み行列は、 入力の単語埋め込み行列の転置と共有されます。
語彙サイズが数万規模になると、この重み行列だけで 数千万パラメータを占めます。共有することでパラメータ数を削減しつつ、 「似た意味の単語は似たベクトルを持つ」という埋め込みの性質を出力層でも活用できます。
6. なぜSelf-Attentionなのか──RNN・CNNとの比較
Transformerの設計選択の核心は「なぜSelf-Attentionなのか」です。 論文は計算量・並列性・長距離依存の3軸でRNN・CNNと比較しています。
6.1 計算量の比較
| 観点 | Self-Attention | RNN | CNN(カーネル幅) |
|---|---|---|---|
| 1層あたりの計算量 | |||
| 並列計算 | 完全に可能 | 不可(逐次) | 可能 |
| 長距離の経路長 | 〜 |
:文の長さ、:次元数(512)、:CNNのカーネルサイズ
計算量がそれぞれになる理由
Self-Attention: の計算がの行列積であるため。 単語数が増えると二乗で計算量が増加します。
RNN: 各ステップで隠れ状態に重み行列をかけ、 それをステップ繰り返すため。
CNN: カーネル幅の畳み込みを位置に適用し、 各位置で次元の変換をするため。
NLPの典型的な設定(、)ではのため、 とを比べると Self-Attentionのほうが実質的に小さくなります。
6.2 長距離依存の学習しやすさ
最も重要な優位性は長距離の経路長です。
任意の2単語が「互いの情報をやり取りする」までに何層かかるかを考えます。
文: "The cat that the dog chased ran away"[0] [1] [2] [3] [4] [5] [6] [7]"cat"(位置1)と"ran"(位置6)の関係を学習したい場合:Self-Attention : 1ステップで直接接続RNN : 5ステップ分の情報を順次引き継ぐ必要があるCNN(k=3) : log_3(5) ≈ 3層必要(各層でk=3の範囲しか参照できないため)RNNは情報が層を伝わるたびに変換・圧縮されるため、距離が離れるほど情報が劣化します。 Self-Attentionでは距離に関係なく常に1ステップで直接参照できるため、 長距離の依存関係を損失なく学習できます。
これがTransformerが長文理解に強い根本的な理由です。
7. まとめ
Transformerが革命的だった理由を一言で言えば:
「RNNもCNNも使わず、Attentionだけで、より速く・より精度高く・より汎用的に系列変換を解いた」
ことです。要点を整理すると:
- Multi-Head Self-Attentionで単語間の関係を並列に・多角的に捉える
- 位置エンコーディングでAttentionの「順序盲点」を補う
- 残差接続+Layer Normで深いネットワークを安定訓練
- 任意の2単語間がステップで繋がり、長距離依存を学習しやすい
この設計のシンプルさと汎用性が、NLPを超えて画像・音声・マルチモーダルへと広がった理由です。 BERT・GPT・T5・ViT——現代AIのすべての起点がここにあります。