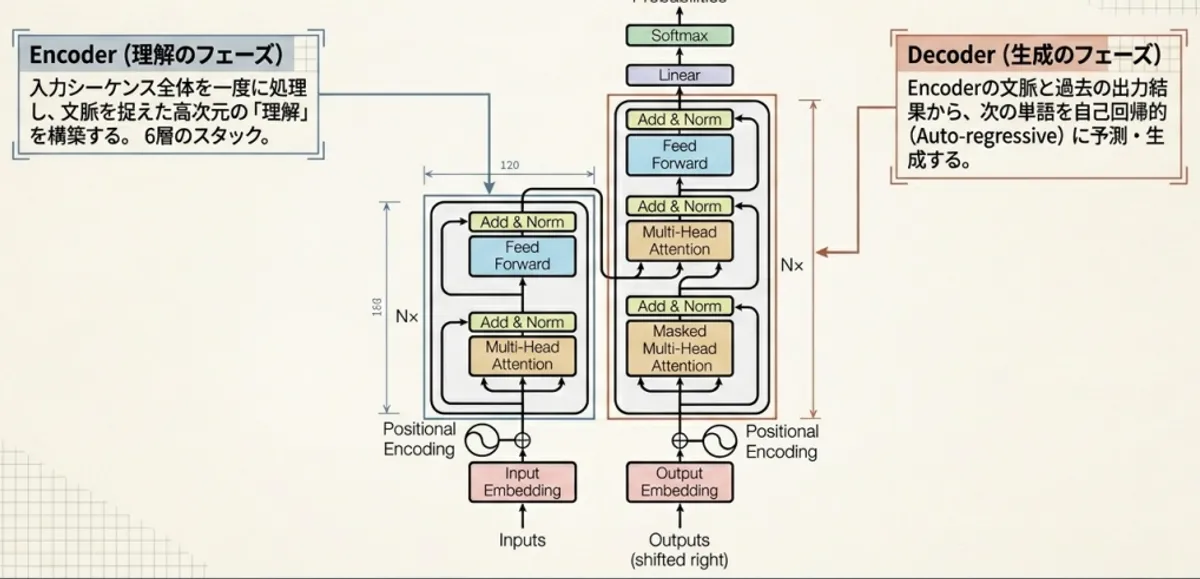
1. はじめに
この記事は、TF-Locoformerを完全解説していこうと思います。記事が長くなってしまうので、今回はPart1です。
TasNetやConv-TasNetの基本的な構造を理解していることを前提としています。それらについて深く知りたいという人は、以下の記事で解説しているのでぜひ読んでみてください。
2. なぜこの研究が必要だったか
2.1 Conv-TasNetまでの流れを確認する
まずは、Conv-TasNetの処理の流れを簡単におさらいしておきましょう。
混合音声(波形) ↓ 【エンコーダ】学習可能な1D Conv潜在表現 ↓ 【分離モジュール】TCN(dilated conv の積み重ね)マスク(0〜1の係数、話者ごと) ↓ 【マスク適用】潜在表現 × マスク ↓ 【デコーダ】転置Conv各話者の波形ここで重要になるのはエンコーダのカーネルサイズです。Conv-TasNetのエンコーダは、波形をおよそ2ms単位で区切って特徴量に変換しています。
2.2「残響」という問題と、Conv-TasNetの限界
屋内で音を録音すると、声が壁や天井に反射した残響が混入します。 残響の厄介な点は、元の声が鳴り終わった後も、反射音が数十〜数百ms遅れて届き続けることにあります。
さて、残響を除去するにはどうすればよいでしょうか?
残響を除去するには、「80ms後に届く反射音」が「最初の直接音」と同じ音源から来ていることをモデルが理解する必要があります。 つまり**少なくとも80ms分の音を同時に見渡せる窓(カーネル)**が必要になります。
Conv-TasNetのエンコーダカーネルは2ms。80msの残響に対して窓が40倍も短いです。 これは設計の工夫でどうにかなる問題ではなく、アーキテクチャが持つ本質的な限界とされています。
2.3 TFドメインに切り替えた理由
そこで注目されたのがSTFT(短時間フーリエ変換)を使うアプローチです。STFTは音声を時間と周波数のスペクトログラムに変換します(STFTの仕組みはPart2で詳しく説明します)。
STFTの窓長は16〜32msが一般的で、残響の遅延をカバーできる長さです。Conv-TasNetより本質的に有利とされています。 さらにモデルがSelf-Attentionで時間軸全体を参照すれば、数百ms先まで見渡すことができます。
本論文で使われるSelf-Attentionとは何かを簡潔に説明します。(詳細はPart2で)
系列の中の全要素が、互いに「どの要素が自分と関係が深いか」を計算し合う仕組みのことです。
具体例で考えてみましょう。「フレーム1〜100」という時系列データがあったとすします。
フレーム: 1 2 3 ... 50 ... 98 99 100 ↕ ↕ ↕ ↕ ↕ ↕ ↕ 全フレームが互いに「関連度スコア」を計算するフレーム50は「フレーム1との関係は薄い、フレーム48・49・51・52との関係が深い」という具合にスコアを計算し、関係が深い相手の情報を多く取り込んで自分の表現を更新していきます。 ここで重要なのは、距離に関係なく全フレームを参照できる点です。フレーム1とフレーム100が遠く離れていても、スコアさえ高ければ互いの情報を直接やり取りできるのです。
これがTFドメインモデルが2022〜2023年に再注目された理由なのです。
2.4 TFドメイン最強モデル「TF-GridNet」の設計
TFドメインのDual-Pathモデルで当時最強の性能を誇っていたのがTF-GridNet(Wang et al. 2023)です。TF-Locoformerはこのモデルの問題点を出発点として設計されているため、まずTF-GridNetの設計を理解することが本論文の問題意識に直結します。
TF-GridNetの設計:RNNとSelf-Attentionの組み合わせ
TF-GridNetが採用したのは、RNNとSelf-Attentionを組み合わせるアーキテクチャです。なぜ片方だけではなく両方が必要だったのでしょうか。
その答えは「音声分離に必要な情報には、性質の異なる2種類がある」という観察から来ています。
ローカルな情報(局所パターン)とは
音声スペクトログラムには、隣り合う周波数ビンや隣り合うフレームが似た値を取りやすいという特性があります。
たとえば人の声にはフォルマントと呼ばれる特徴的な共鳴周波数があります。フォルマントはスペクトル上に「エネルギーの山」として現れ、この山は数ビン〜十数ビンにまたがる滑らかな形をしています。
【フォルマントのイメージ(周波数方向の断面)】
エネルギー↑│ ██│ ████│ ██████│ ████████│ ████████████└──────────────────→ 周波数ビン ↑ 隣接した複数ビンが連続して山を形成 (ビン20はビン18〜22と強く相関している)「ビン20のエネルギーが高い」なら「隣のビン19やビン21も高い可能性が高い」——このような近傍との相関構造を捉えるには、モデルが近くのビンを参照して判断することが不可欠です。これが「ローカルな情報」です。
グローバルな情報(大域パターン)とは
一方、1フレームや1ビンだけを見ても分からない情報もあります。
たとえば「話者Aと話者Bを分離する」タスクでは、各話者の声の全体的な周波数特性が重要な手がかりになります。
【話者の大域的な周波数特性のイメージ】
話者A(男性) 話者B(女性)低域(0〜2kHz) ████████████ ████中域(2〜4kHz) ████████ ████████████高域(4〜8kHz) ████ ████████「話者Aは低域が強い」という知識は、スペクトル全体を見渡して初めて得られます。1ビンだけを見ていてもこのパターンは分かりません。
また「フレーム1で話者Aの声があった」という情報を「フレーム100に現れた音は誰のものか」という判断に活かすには、時間軸で遠く離れた位置同士を直接結びつける必要があります。これが「グローバルな情報」です。
TF-GridNetの役割分担
TF-GridNetでは、この2種類の情報をそれぞれ得意なモジュールに割り当てていました。
| 情報の種類 | 担当モジュール | 理由 |
|---|---|---|
| ローカルな情報(近傍の相関) | RNN | 構造的に近傍を重視する(次節で詳説) |
| グローバルな情報(大域的パターン) | Self-Attention | 全位置を1ステップで直接参照できる |
この役割分担が効果的に機能したことで、TF-GridNetは当時最高のスペクトル分離性能を達成しました。
2.5 RNNがローカルに強い理由を理解する
前節でRNNが「ローカルな情報を担当する」と述べました。なぜRNNはローカルな情報の取得に向いているのでしょうか。まずRNNを初めて学ぶ方のために、その仕組みを簡単に説明します。
**RNNは「記憶を持つニューラルネット」**です。
通常のニューラルネットは入力を受け取って出力するだけで、過去の入力を記憶しません。RNNは隠れ状態(hidden state)h(t) という内部メモリを持ち、入力を受け取るたびにこのメモリを更新しながら処理を進めます。
時刻1 → x(1) → [RNN] → h(1) → 出力1時刻2 → x(2) → [RNN] → h(2) → 出力2 ← h(1)の情報を引き継いでいる時刻3 → x(3) → [RNN] → h(3) → 出力3 ← h(2)→h(1)の情報が積み重なっている時刻 t での隠れ状態 h(t) には「時刻1から時刻tまでの入力の蓄積」が含まれているため、音声・テキストのような時系列データの処理が得意とされてきました。
RNNの更新式
RNNの核心となる更新式は以下のとおりです。
過去の記憶 現在の入力 ↓ ↓h(t) = f( W_h × h(t-1) + W_x × x(t) ) ↑ ↑ 1ステップ前の隠れ状態に 今この瞬間に 重み行列 W_h をかける 入ってきた情報f は活性化関数(tanhなど)、W_h と W_x は学習可能な重み行列です。
ここで重要なのは、h(t) が h(t-1) と x(t) だけから計算されるという点です。2ステップ以上前の情報は h(t-1) の中に間接的に含まれているだけです。
なぜ遠い情報が届きにくいのか
x(t-5) の情報が h(t) に届くまでに何が起きるか、追ってみましょう。
x(t-5) → h(t-5) ↓ W_h で変換 h(t-4) ↓ W_h で変換 h(t-3) ↓ W_h で変換 h(t-2) ↓ W_h で変換 h(t-1) ↓ W_h で変換 h(t) ← x(t-5)の情報はここに間接的にしか届かない情報は毎ステップ W_h という行列で変換されながら伝わります。この変換を繰り返すたびに、元の情報は少しずつ変質・希薄化していきます。
わかりやすいたとえで言うと「電話ゲーム」です。最初のメッセージが10人を経由するうちに変わってしまうように、RNNも遠い過去の情報ほど正確には届きません(これを勾配消失問題といいます)。
数値で確認してみましょう。W_h の最大固有値が0.9だとすると:
1ステップ前: 0.9^1 ≈ 0.90(ほぼそのまま)3ステップ前: 0.9^3 ≈ 0.73(少し薄れる)10ステップ前:0.9^10 ≈ 0.35(かなり薄れる)50ステップ前:0.9^50 ≈ 0.005(ほぼ消える)近いステップの情報ほど強く残り、遠いステップの情報ほど薄れていきます。
これはアーキテクチャの構造から来る性質であり、学習でどうにかできるものではありません。
TFドメインでこの性質が活きる理由
周波数方向にRNNを適用するとどうなるか、考えてみましょう。
ビン1 → h(1)ビン2 → h(2) ← h(1)の情報を強く持っている(1ステップ前)ビン3 → h(3) ← h(2)の情報を強く、h(1)の情報を少し持っている...ビン20 → h(20) ← ビン19・18の情報を強く、ビン1の情報はほぼない「ビン20の処理」では「ビン18, 19」の情報が強く反映され、「ビン1」の情報はほとんど反映されません。これはまさに、フォルマントのような「隣接ビン間の相関」を捉えるのに適した性質です。
モデルに「近くを重視せよ」と明示的に指示しなくても、アーキテクチャが自動的に近傍バイアスを持ちます。これがRNNがローカルモデリングに強い根本的な理由です。
2.6 RNNの根本的な問題
RNNには一つ致命的な欠点がありました。
更新式を見ると分かるように、時刻tの計算は時刻t-1の計算が終わらないと始められません。
どんなに多くのGPUがあっても逐次的にしか計算できず、音声1秒分(T=125フレーム)を処理するには、必ず125ステップ待つ必要がありました。
これに対しSelf-Attentionは、時刻1〜Tをまとめて並列処理できるので、GPUで全フレームを同時計算できるといった利点がありました。
学習速度・スケーリング・将来的なモデル改善のしやすさなど、Transformerには多くの利点があり、RNNを使い続ける限りこれらの恩恵を受けられないことが明らかになってきました。
2.7 「じゃあRNNをTransformerに変えれば?」——試されたが失敗した
「RNNをSelf-Attentionに置き換えればよい」という発想は当然で、既に試されていました。しかしTFドメインでは性能が出なかった。これが本論文の出発点です。
なぜ失敗したのでしょうか。
2.7.1 まずSelf-Attentionが「全てを等しく参照する」とはどういうことか
Self-Attentionは直前のセクションで説明したように、「全要素が互いに関連度スコアを計算し合う」仕組みです。
ここで重要なのは、そのスコアが最初はランダムから学習によって決まるという点です。
学習前(初期状態): フレーム50 → フレーム49との関連度: 0.3(ランダム) フレーム50 → フレーム51との関連度: 0.7(ランダム) フレーム50 → フレーム1 との関連度: 0.5(ランダム) フレーム50 → フレーム100との関連度:0.2(ランダム)
学習後(理想): フレーム50 → フレーム49との関連度: 高い(近傍が重要) フレーム50 → フレーム51との関連度: 高い(近傍が重要) フレーム50 → フレーム1 との関連度: 低い(遠くは無関係) フレーム50 → フレーム100との関連度:低い(遠くは無関係)「近傍を重視するスコア」はあくまで学習によって獲得するもので、アーキテクチャが最初から保証してくれるものではありません。
これ自体は問題ではありません。学習さえうまくいけば近傍バイアスを獲得できます。問題は次にあります。
2.7.2 時間領域Dual-Pathではなぜうまくいったか
SepFormer(Subakan et al., 2021)のような時間領域Dual-PathモデルにTransformerを適用したモデルは、波形をそのままAttentionにかけるのではなく、まず小さいチャンクに分割してからAttentionをかけます。
【チャンク分割のイメージ】
元の系列(全1000フレーム): [1, 2, 3, 4, 5, 6, 7, 8, ... , 1000]
チャンクサイズ=100で分割: チャンク1:[1〜100] チャンク2:[101〜200] チャンク3:[201〜300] ...
Intra-Chunk Attention(チャンク内): チャンク1の中だけでAttentionをかける → フレーム1〜100の範囲しか参照できない → 物理的にフレーム500は見えないチャンクサイズが100なら、Intra-Chunk Attentionはどんなにスコアをつけようとしてもチャンク外のフレームを参照できません。
アーキテクチャの構造が「近傍しか見られない」状態を強制しているのです。
2.7.3 TFドメインではなぜ同じことが出来ないのか
TFドメインのDual-Pathでは周波数ビンを系列として扱います。
たとえば周波数ビンが256個あるなら、256個を1本の系列としてそのままAttentionにかけます。
【周波数方向のAttentionのイメージ】
周波数ビン:[1, 2, 3, 4, ... , 128, 129, 130, ... , 256]
時間領域のようにチャンクで区切ると? チャンク1:[1〜50] チャンク2:[51〜100] ...
→ 問題:周波数軸でのチャンク分割は意味をなさない 周波数ビン1〜50とビン51〜100は 「時間的に連続」ではなく「周波数が連続」しているだけ。 話者の声のパターンは全周波数帯にまたがることも多く、 チャンクで区切ると肝心な情報が断ち切られてしまう。時間軸のチャンク分割は「直近の音は関係が深く、遠い過去は薄い」という音声の性質に沿っています。
しかし周波数軸には同じ論理が成り立たちません。低域と高域がどちらも重要な場合も多く、どこで区切っても不自然になってしまいます。 そのため、TFドメインでは「チャンク分割でローカル性を強制する」という時間領域の解決策が使えないのです。
ここまで、長くなってしまったのでまとめます。
【時間領域モデルの場合】 Attentionの前にチャンク分割がある → 構造的に「近傍しか見られない」状態を保証 → Attentionは自然とローカルパターンを学ぶ
【TFドメインモデルの場合】 周波数ビン全部をそのままAttentionにかける → 近傍も遠距離も等しく参照できてしまう → 「近傍を重視せよ」という誘導が何もない → フォルマントのような局所的なパターンを 学習するのが構造的に難しい
RNNはこの問題を近傍バイアスが構造に組み込まれていることで自然に解決していました。 Transformerにはそれがありません。なのでTFドメインではRNNの方が強かったのです。
では「学習で頑張れば近傍バイアスを獲得できるのでは?」
理論的にはそうかもしれません。しかし実際には難しく、理由が2つあります。
- 学習の非効率性
「遠くのビンは無視してよい」という知識を、Attentionは全部の組み合わせを試した上で学習しなければなりません。 最初から近傍しか見られないモデルと比べて、無駄な計算と学習コストがかかってしまいます。
- 汎化しにくい 「このデータではビン50とビン51が関連する」と学習しても、それが「近傍性の原則」として汎化されるとは限りません。 RNNやConvのように「近傍を参照する」という帰納バイアスが構造に焼き込まれている方が、より少ないデータで汎化しやすいです。
2.8 本論文のアイデア
ここまで整理すると、問題が明確になっていきます。
【解決すべき問題】TFドメインのDual-Pathモデルで: ✓ グローバルな情報はSelf-Attentionで捉えられる ✗ ローカルな情報を捉える仕組みがない → RNNがこの役割を担っていたが、RNNは並列化できない → RNNなしにローカル情報を捉えたいTF-Locoformerの答えはシンプルで以下の通りです。
【解決策】Self-AttentionのFFN(Feed-Forward Network:全結合変換層のこと。詳細はPart2・3で解説)を「畳み込み付きFFN(ConvSwiGLU)」に置き換える
畳み込みは物理的に近傍しか参照できない→ 構造的にローカルモデリングを担保できる→ RNNと同じ役割をConvで代替できるこの一文が論文全体の核心です。次の第2部ではアーキテクチャの具体的な中身を見ていきます。