1. はじめに
複数人が同時に話す部屋で、特定の人の声だけを聴きとる。
人間には自然にできるこのカクテルパーティー問題が、機械にとっては長年の難題でした。 これが音源分離という研究領域です。
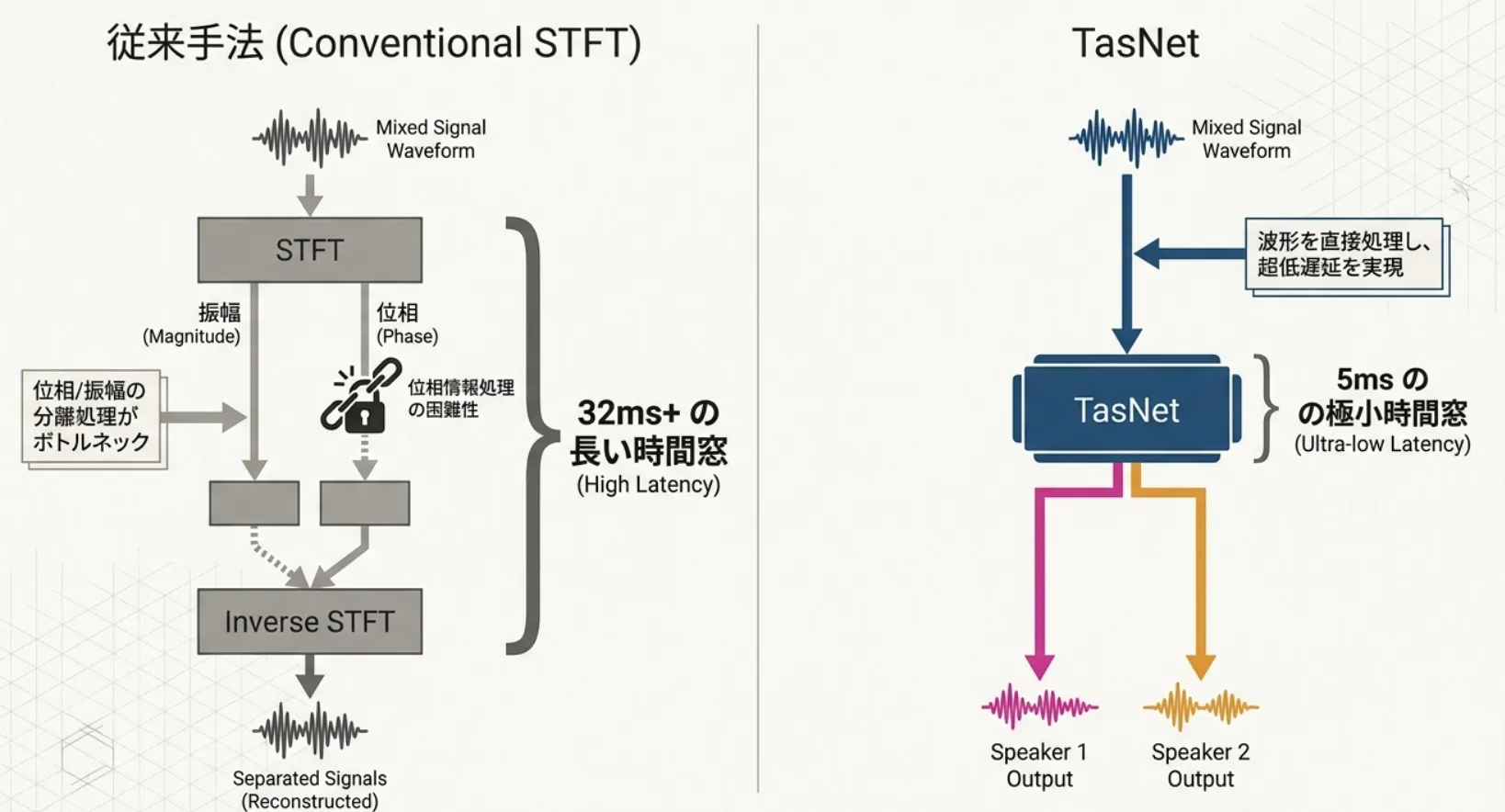
音源分離において、STFTを用いて音声を周波数領域に変換してから音源分離する手法が主流でした。 しかし2018年ごろから、フーリエ変換を使わず、時間領域で特徴量に変換して音声にマスクをかけることで音源分離する手法 が増えてきました。今回はその中でも特に有名なTasNetについて、論文を読み込んで完全解説します。
2. 解きたい問題
マイク1本で録音した2人が同時に話している音声から、それぞれの声を取り出したい。
これだけ聞くとシンプルですが、逆問題なので難しいです。逆問題とは、答えが一意に定まらない問題のことです。
従来の手法ではSTFTという手法が用いられていました。フーリエ変換で周波数成分に分解してから分離という手法です。 しかし、STFTは
- フーリエ変換が音源分離に最適か不明
- 位相を扱えないので精度に限界がある
- 最低32msの処理遅延が生じる
といった問題を抱えていました。
そこで、2018年にTasNetという手法が提案されました。 フーリエ変換を扱わず、波形を直接扱うことでこれらを全部解決しようとしたのです。
3. モデルの説明
3.1 問題の定式化
まずは、今回の論文で定式化されている問題の意味を理解していきましょう。
3.1.1 音声のデジタル表現
音声は1秒間に8000個の数値が並んだ配列です。
混合音は各話者の音声の足し算で表されます。
が与えられたときとを求めるのが今回の目標です。
3.1.2 セグメント分割
ここで、4秒間の音声(32000サンプル)を一度に処理するのは大変なので、長さサンプルの塊に分けます。
したがって個のセグメントに分けられます。
3.1.3 基底信号による表現
まず「基底」の直感を掴みましょう。線形代数で習った「ベクトルを基底の線形結合で表す」のと全く同じ発想です。
TasNetでは音声セグメント(長さ40の波形)を 種類の波形パターン(基底信号)の線形結合で表します。
| 記号 | 意味 | サイズ | 具体的なイメージ |
|---|---|---|---|
| 入力セグメント | 5ms分の波形 | ||
| 基底信号の集合 | 500種類の「音のパターン」 | ||
| 各基底の重み | 「どのパターンがどれだけ含まれるか」 |
展開すると以下のようになります。
フーリエ変換もsin波・cos波という基底の線形結合ですよね。それと全く同じ構造です。違いは基底がsin/cosではなく、ニューラルネットが学習で決めることです。
ここで、重みは非負であるという制約を課します。なぜ必要かを具体例で見てみましょう。
音声は加法性があるので、混合音の重みと各話者の重みの間には、
が成立します。
もし非負という制約がなくなってしまうと、解釈が難しくなってしまいます。
例えば、ある次元でが0.8だったとします。 もしが0.7、が-0.1だったら、 話者1の寄与は0.7で話者2の寄与は-0.1という意味になります。
これだと「話者2はこの次元に対してマイナスの影響を与えている」といった解釈になってしまい、分離問題としては扱いづらくなってしまうというわけです。
全要素が非負であれば、比率が必ず0~1の範囲に収まり「どちらの声がどれだけ含まれているか」という割合として自然に解釈できます。
3.1.4 マスクとは何か
マスクは「混合音の重みを、話者1と話者2でどれだけ分け合うか」を表す割合です。
w_k = [0.8, 0.3, 0.5, ...] ← 混合音(2人が混ざっている)
m₁,k = [0.9, 0.2, 0.8, ...] ← 話者1の取り分m₂,k = [0.1, 0.8, 0.2, ...] ← 話者2の取り分 ↑各次元で足すと必ず1.0マスクを掛け算することで、各話者の重みを取り出せます。
全要素が非負なので、各話者の寄与を割合で表せます。
ここで勘違いしてほしくないのは、は混合音の重みであって、話者1や話者2の重みではないということです。
は「このセグメントには基底信号のパターンがどれだけ含まれているか」を表すベクトルです。 話者1の重みは、話者2の重みはです。
あとは基底信号を重みで重ね合わせることで、各話者の波形を復元できます。
なぜなら、基底信号はエンコーダとデコーダで共有されており、ニューラルネット全体を通じて誤差逆伝播で学習されるからです。
以上をまとめると、TasNetの分類問題は次のように言い換えられます。
混合音の重み から各話者のマスク を推定する問題
マスクさえ推定できれば、あとは掛け算と規定新語の重ね合わせだけで各話者の波形が復元できます。これがTasNetの革新的なアイデアです。
3.2 エンコーダ(波形 → 重み)
問題を定式化できたところで、実際に処理の流れを追っていきましょう。 全体の流れとしては以下の通りです。
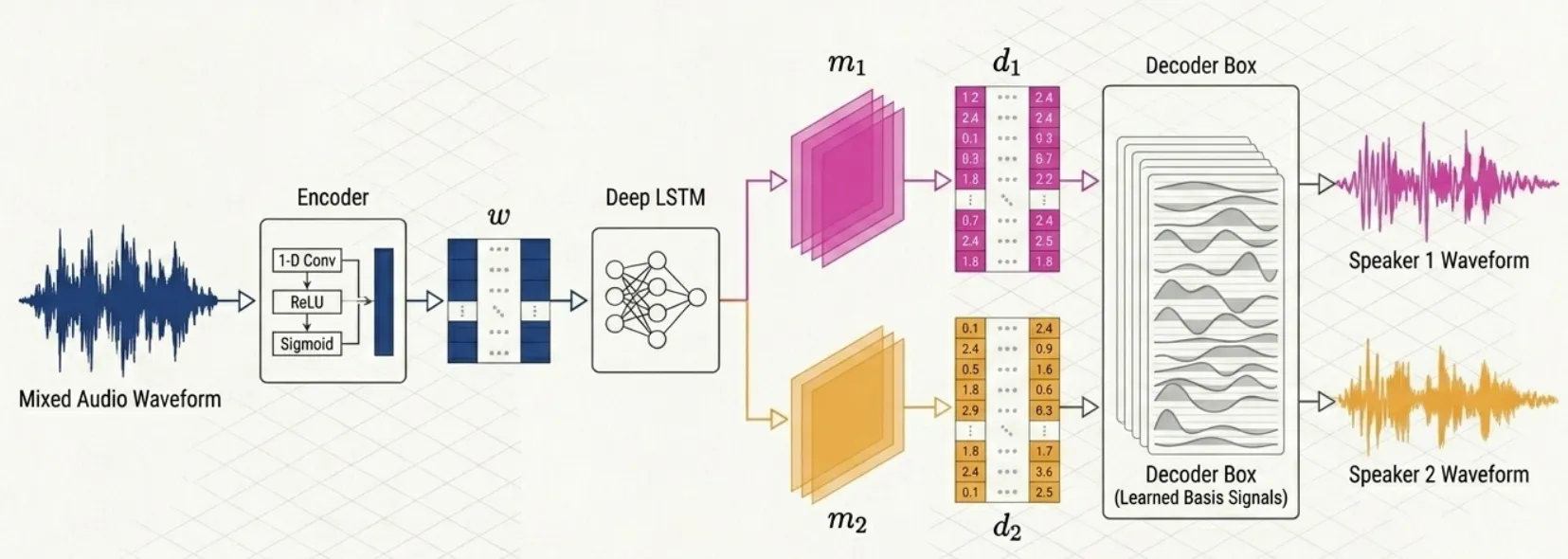
まずは、入力信号をエンコーダに通します。
役割としては、音声セグメント を重みベクトル に変換します。
3.2.1 前処理:L2正規化
まず入力信号をエンコーダに通す前に、正規化します。
これで になります。音量の大小によらず、波形の形だけを見るようになります。
3.2.2 1次元畳み込み(1D Convolution)
前処理が終わったら、実際にエンコーダに通していきます。
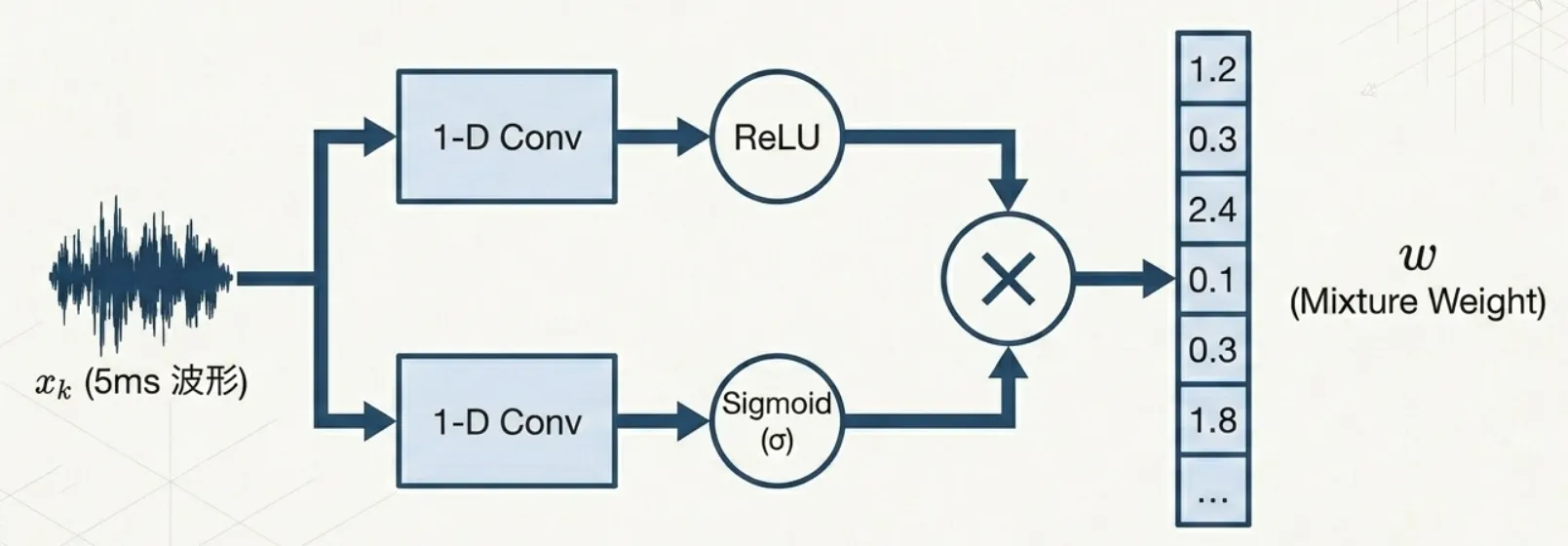
エンコーダの計算式は以下の式で表されます。
初見だとこの式が何をいっているのか全く分からないと思います。まずは、内積・ReLU・Sigmoidの3つの要素の復習から行いましょう。
まずの部分を理解しましょう。 を実際に計算すればわかりますが、要は内積を500回行っています。
ところで、内積は類似度を表します。直感的なイメージとしては、が小さい(向きが近い)ほど内積が大きくなるといった具合です。
つまり、ここでいう内積の値というのは、そのフィルタのパターンがどれだけ含まれているか、500種類のパターンとの類似度を調べているわけです。
とてもシンプルで、負の値を0にする関数です。数式で表すと
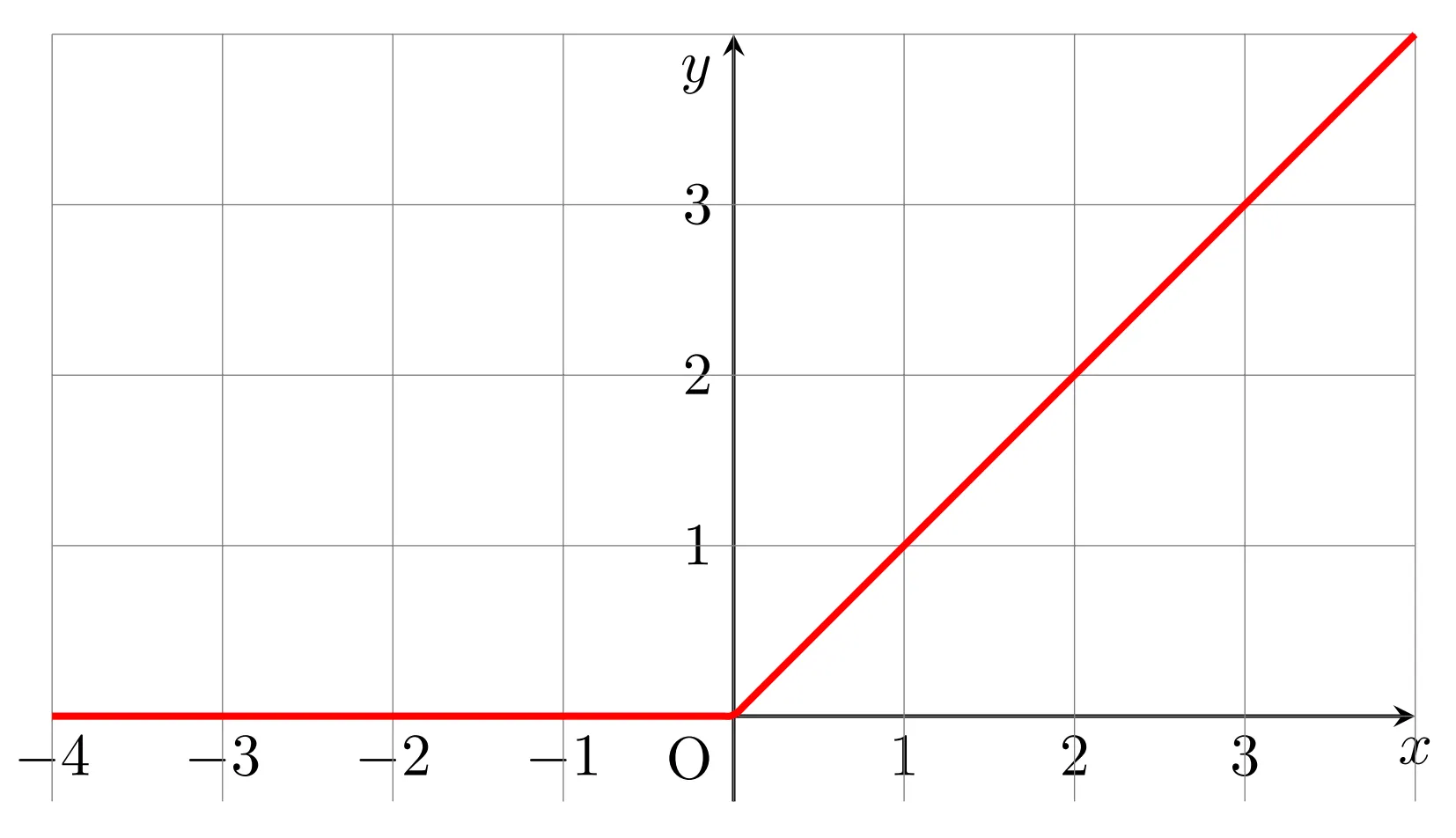
先ほど述べた通り、重みベクトルは全要素非負である必要があるので、ReLUを使って負の値を0にしています。
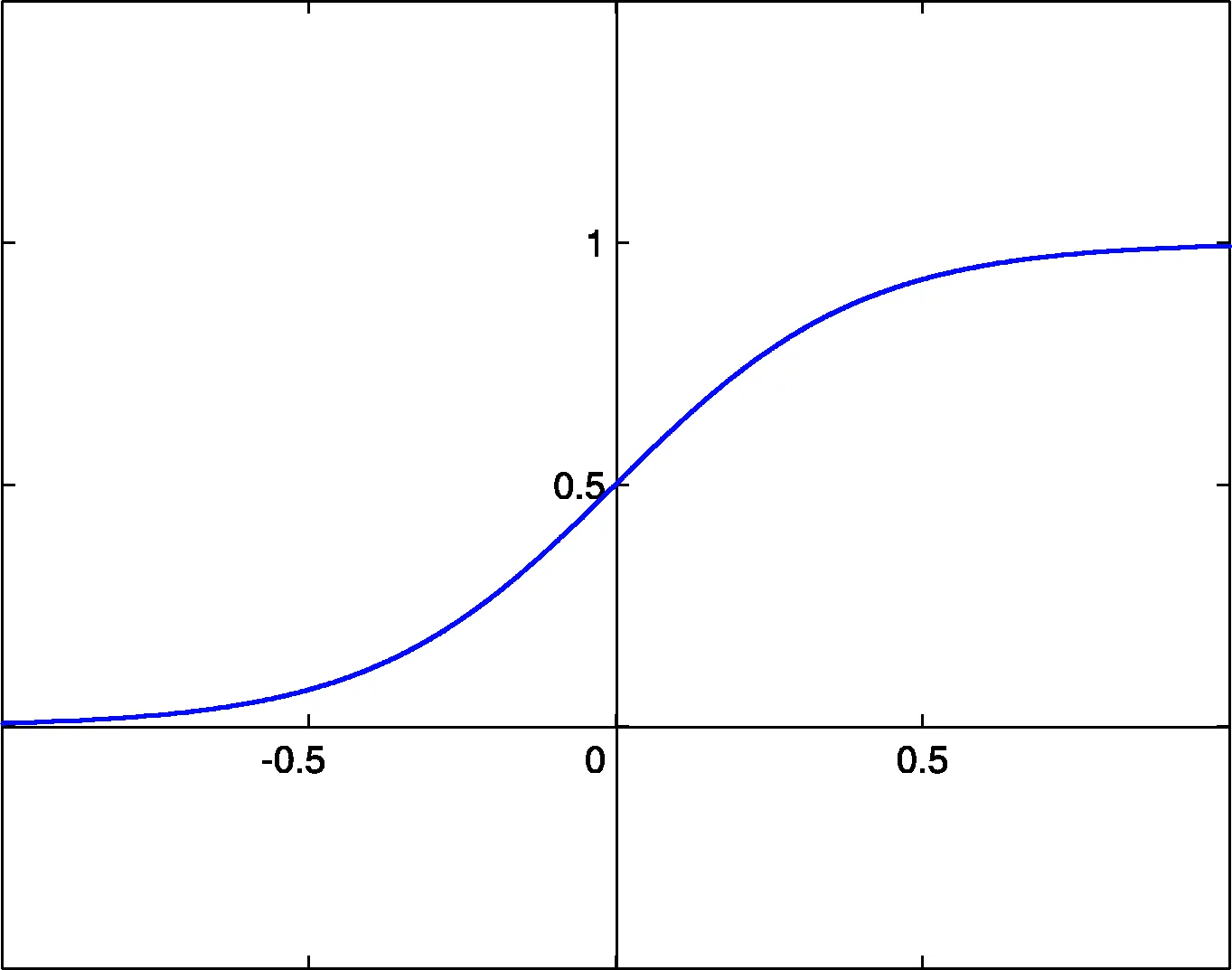
値域が なので「どれだけ通過させるか」の割合として機能します。
ここで、もう一回さっきの式に戻ってみましょう。
混合音の重みを得るために、特徴量とゲートの2つの要素を掛け合わせているというわけですね。
ここでとは、最初はランダムに初期化され、学習で自動的に決まるパラメータです。
ReLUだけでは「ある/なし」しか言えませんが、ゲートがあると「あるけど今は使わない」という判断ができます。これが性能向上の鍵です。
3.3 分離ネットワーク(重み → マスク)
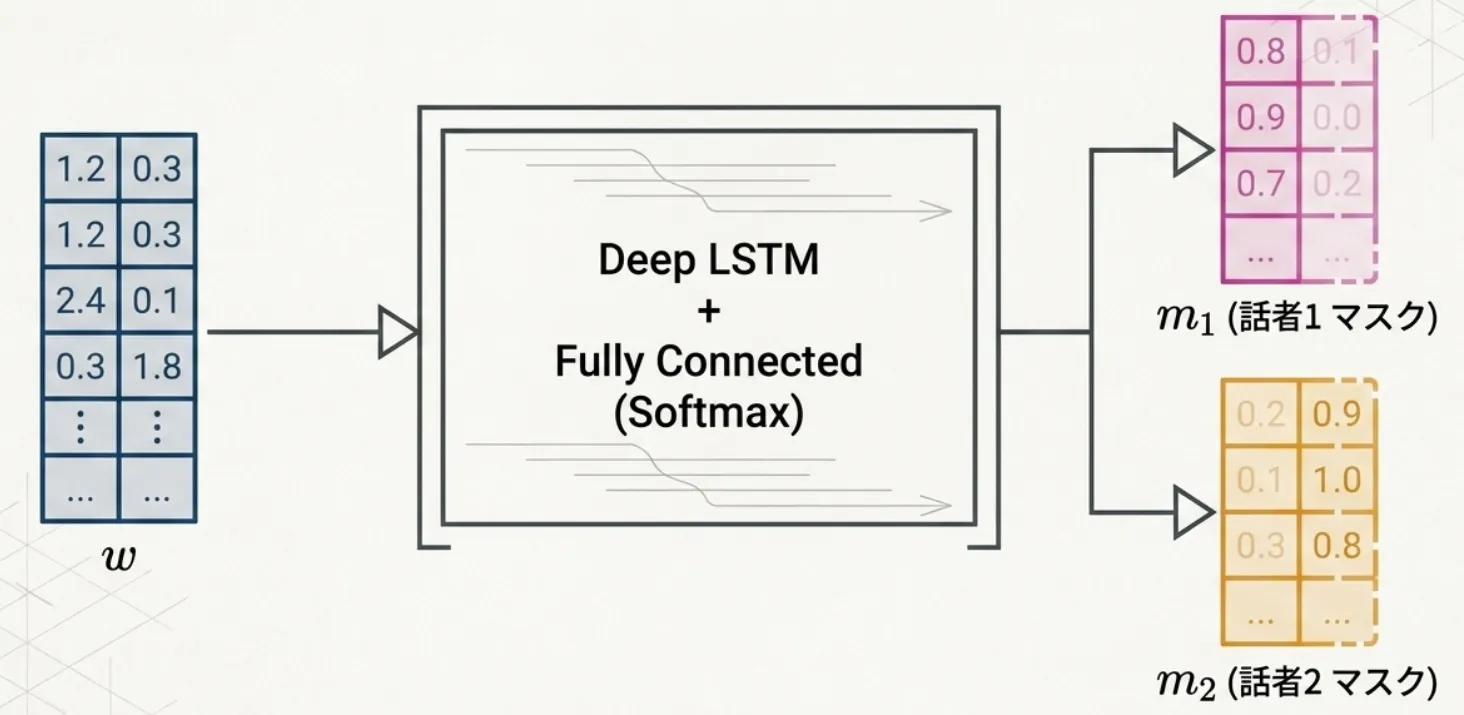
ここまでで、エンコーダを通して800個の重みベクトルが得られました。 次に各話者のマスク、を推定します。
ここで問題になるのが、どのネットワークでマスクを推定するかです。 マスクの推定は「800個の重みベクトルの時系列を入力として、各セグメントごとに各話者のマスクを出力する」タスクです。この時系列を扱うネットワークとして選ばれたのがLSTMです。
なぜLSTMが採用されたのかはここでは詳しくは説明しませんが、過去の情報を選択的に記憶・忘却する仕組みとでも理解しておいてください。
3.3.1 層正規化(Layer Normalization)
ここで、LSTMに渡す前に、混合音の重みベクトルの値のスケールを揃えます。
たとえば、
w_k = [0.001, 0.002, ..., 0.0005] ← スケールが小さいw_k = [100, 200, ..., 50] ← スケールが大きいという状態でLSTMに渡すと、学習が不安定になってしまいます。そこで、標準化を行います。
を平均、を標準偏差すると、 以下の式で標準化できます。
この式を基に重みベクトルを標準化してみましょう。
に対して、平均を計算すると、
次に標準偏差は、
となります。これを用いて、重みベクトルの各要素を標準化すると、以下のようになります。
ここからが重要です。
このままだと全セグメントが必ず平均0・分散1に固定されてしまいます。
そこで、スケーリングとシフトを行います。具体的には以下の処理を行います。
(ゲイン)と (バイアス)は学習で決まるパラメータです。
このような層正規化を行ったのち、LSTMに渡してマスクを推定していきます。
3.3.2 スキップ接続(Skip Connection)
LSTM層を重ねるはど複雑なパターンを学習できます。本論文では、4層のLSTMを重ねていますが、層を重ねると勾配消失問題が悪化するという問題があります。そこで、スキップ接続を導入します。 しかし層が深くなると、学習がうまくいかなくなる問題が発生します。
ニューラルネットの学習は出力の誤差を逆向きに伝えて各層のパラメータを修正する仕組みです。
【前向き(推論)】入力 → LSTM層1 → LSTM層2 → LSTM層3 → LSTM層4 → 出力
【逆向き(学習)】入力 ← LSTM層1 ← LSTM層2 ← LSTM層3 ← LSTM層4 ← 誤差誤差が層を通るたびに、0~1の小さな数が掛け算されます。そうなると、層が深いほど、浅い層に届く誤差がほぼゼロになります。 誤差がゼロということは「どう修正すればいいかわからない」ということなので、浅い層のパラメータがほとんど更新されなくなります。 これが勾配消失問題です。
これを解決するために、スキップ接続という手法が導入されています。 ここでは、2層目の出力を、4層目の入力に直接足し合わせる構造を採用しています。
入力 ↓LSTM層1 ↓LSTM層2 ─────────────────┐ ↓ │LSTM層3 │(恒等写像 = そのままコピー) ↓ │LSTM層4 ←────────────────┘(足し算) ↓出力数式で書くと、以下のように表せられます。
近道があることで、浅い層も正しく学習できるということですね。
3.3.3 マスクの生成
ここまでの流れを確認してみましょう。
- エンコーダで重みベクトルを得る
- 層正規化を行う
- LSTMで時系列を処理する
- スキップ接続で学習を安定させる
次のステップはLSTMの出力からマスクを生成し、各話者の重みを取り出すことです。
ここで、マスクの意味をおさらいしておきましょう。
マスクとは「混合音の重みを、話者1と話者2でどれだけ分け合うか」を表す割合のことです。
マスクが0.7なら「その次元の重みの70%は話者1、30%は話者2」という意味になります。したがって、マスクと重みを掛け算すれば、各話者の重みが得られます。
マスクを得るために、まず全結合層でLSTMの出力を、重み行列を使って、マスクの次元に変換します。
今回は1000次元→1000次元(話者1・2それぞれ500次元)に変換しています。
このの値はどんな値でもあり得ます。しかし、マスクとして使うには0~1に収める必要があります。そこでSoftmaxを使います。
Softmax関数は複数の値を合計が1になる割合に変換する関数です。
2話者の場合、次元ごとに
となります。念のため足し合わせてみます。
このように、Softmaxを使うと、混合音の各次元を2人で合計100%になるよう分け合うことができます。
3.4 デコーダ(重み → 波形)
次にデコーダについてみてみましょう。
デコーダはエンコーダの逆演算です。話者 の重み行列 から元の波形 を復元します。
- エンコーダ:波形を重みベクトルに変換するネットワーク
- デコーダ:重みベクトルを波形に変換するネットワーク
デコーダの計算式は以下のように表されます。
- :全セグメントの重み
- :基底信号(エンコーダと同じ )
- :全セグメントの復元波形
1セグメント で見ると、計算の意味が分かりやすくなります。
「重みに従って基底信号を重ね合わせる」= エンコーダの逆演算(転置畳み込み)です。
最後に 個のセグメントを順番に並べれば、完全な話者 の波形が得られます。
基底信号 はエンコーダとデコーダで共有されており、ニューラルネット全体を通じて誤差逆伝播で学習されます。「音声分離に最適な基底」が自動的に決まります。
3.5 損失関数(SI-SNR と PIT)
3.5.1 SI-SNR(スケール不変信号対雑音比)
学習には推定した波形が正解にどれだけ近いかを測る指標が必要です。それがSI-SNRです。
SI-SNRが高いほど推定波形が正解に近く、学習がうまくいっています。
まず、両方の波形から平均を引きます。この処理を施すことで、全体的なオフセットの影響を除去します。
この次が最も重要なステップです。推定波形を正解波形の方向に正射影することで、正解波形の成分を抽出します。
これは を の方向に正射影したものです。高校数学・線形代数で習いましたね。
ŝ(推定) /| / | / | e_noise(ノイズ成分) / | / θ |───/─────┼──────→ s の方向 s_targetちなみに、先ほどの式の表記がわからない人もいるので、載せておきます。
- : と の内積。類似度を表す。
- : のノルムの2乗。ベクトルの大きさを表す。
ここで求められた は、推定波形のうち、正解波形の方向にある成分を表しています。
正解波形から正解方向の成分を引くと、誤差成分が得られます。
最後にSI-SNRを計算します。
「正解方向の成分」が「誤差成分」より何dB大きいか、です。
SI-SNRを計算したら、とをどう変えれば分離がうまくいくかを誤差逆伝播で学習します。
とを少しずつ更新・繰り返しを重ねることで、 最終的に「音声分離に最適なと」に収束します。
3.5.2 PIT(Permutation Invariant Training)
以上の操作を経て、TasNetは2人分の音声を分離して出力1と出力2を得ることができます。
しかし、ここである問題が生じます。
出力1がAさん、出力2がBさんになるとは限らないのです。
どちらのパターンで出力されるかは、学習の状況によって変わります。
学習では「出力と正解を比べてSI-SNRを計算する」必要があるのですが、正解の対応が間違っていると、SI-SNRが正しく計算できません。
そこで、PITという手法が導入されました。
PITはすべての対応を試して、SI-SNRが最大の対応を採用します。2話者の場合、対応のパターンは2通りです。
パターンA: 出力1⇔正解1、出力2⇔正解2パターンB: 出力1⇔正解2、出力2⇔正解1PITは両方のパターンでSI-SNRを計算して、どちらのパターンが今のネットワーク出力にとって一番都合が良いかを毎回選んで学習します。これにより順列問題を回避できます。
4. 全体のまとめ
以上、TasNetの処理の流れでした!
最後に全体の流れをまとめてみましょう。
【問題】混合音 x(t) = s₁(t) + s₂(t) から s₁, s₂ を分離したい
【TasNetの解き方】
x(t) ↓ L=40サンプルに分割 x_k (5ms) ↓ L2正規化 x̂_k ↓ Gated 1D-Conv(エンコーダ) w_k ∈ R^500 (非負) ← 500個の基底への重み ↓ Layer Normalization ŵ_k ↓ 4層LSTM + FC + Softmax(分離ネットワーク) m₁,k, m₂,k ∈ R^500 ← 各話者のマスク(合計=1) ↓ d_{i,k} = m_{i,k} ⊙ w_k d_{i,k} ← 各話者の重み ↓ D_i × B(デコーダ) S_i ← 各話者の復元セグメント ↓ K個を連結 sᵢ(t) 完成5. 実験のまとめ
本記事は、TasNetのモデル構造や処理の流れを中心に解説してきましたが、最後に実験結果も簡単にまとめておきましょう。
データセット
2人が同時に話す音声データ「WSJ0-2mix」を使用しています。
- 訓練セット:30時間
- 検証セット:10時間
- 評価セット:5時間(学習に使っていない未知の16人)
評価に未知の話者を使うことでどんな人の声でも分離できるかを確認しています。
5.1 結果
リアルタイム・非リアルタイムどちらでも従来手法を上回りました。また、学習済みの基底信号フーリエ変換して可視化すると、500個中60%が1kHz以下の低周波に集中していました。
これは、人の声の重要な情報が低周波に多く含まれていることを示しています。
基底信号が学習で自動的に決まるため、音声分離に最適な基底が自然と学習されるということですね。
6. まとめ
- TasNetは、音声セグメントを基底信号の線形結合で表すというアイデアが革新的
- エンコーダで重みベクトルを得て、分離ネットワークでマスクを推定し、デコーダで波形を復元する構造
- SI-SNRとPITを使って学習し、従来手法を上回る性能を達成
TasNetは優れた手法でしたが、分離ネットワークにLSTMを使っていることで、2つの問題がありました。
- 計算が遅い:LSTMは時系列を順番に処理するため、並列化が難しい
- 長期依存関係の学習が難しい:LSTMは長い時系列を扱うのが苦手で、長期的なパターンを学習するのが難しい
これらの問題を解決するために、Transformerベースの分離ネットワークを採用した改良版のTasNetも提案されています(Conv-TasNet)。
Conv-TasNetの説明とLSTMの説明についても追々、別記事で解説していきたいと思います!
長くなってしまいましたが、ありがとうございました!
7. 参考文献
Luo, Y., & Mesgarani, N. (2018). TasNet: Time-Domain Audio Separation Network for Real-Time, Single-Channel Speech Separation. ICASSP 2018. arXiv:1711.00541
Hershey, J. R., Chen, Z., Le Roux, J., & Watanabe, S. (2016). Deep Clustering: Discriminative Embeddings for Segmentation and Separation. ICASSP 2016. (WSJ0-2mix データセットの出典)
Yu, D., Chang, X., & Qian, Y. (2017). Permutation Invariant Training of Deep Models for Speaker-Independent Multi-Talker Speech Separation. ICASSP 2017. (PIT の提案論文)
Isik, Y., Le Roux, J., Chen, Z., Watanabe, S., & Hershey, J. R. (2016). Single-Channel Multi-Speaker Separation Using Deep Clustering. Interspeech 2016. (DPCL++ の原論文)
Chen, Z., Luo, Y., & Mesgarani, N. (2017). Deep Attractor Network for Single-Microphone Speaker Separation. ICASSP 2017. (DANet の原論文)
関連記事
Conv-TasNet完全解説
Conv-TasNetは、音源分離の分野で画期的な性能を示した深層学習モデルです。LSTMからTCNへの置き換えによって何が変わったのか、アーキテクチャの工夫を丁寧に解説します。
【Part2】TF-Locoformer 完全解説
TF-Locoformerのアーキテクチャを一から丁寧に解説します。STFTによる入力表現・Dual-Path構造・マカロン型Transformerブロックを図解します。
【Part3】TF-Locoformer 完全解説
ConvSwiGLU・RMSGroupNormの技術詳細と実験結果を解説します。TF-Locoformerがどうやってローカルな情報を取得し、どれだけ性能を改善したかを明らかにします。