1. はじめに
TasNetはフーリエ変換を使わず時間領域で音源分離するという革新的なアイデアで注目されました。 しかし分離モジュールにLSTMを使っていたため、速度・サイズ・安定性の面で課題がありました。
この記事では、それらを全て解決した改良版 Conv-TasNet を解説します。LSTMの代わりに Temporal Convolutional Network(TCN) を使うことで、パラメータ数を約5分の1に削減しながら、精度をさらに向上させています。
この記事は、TasNetの基本的な構造を理解していることを前提としています。TasNetについて深く知りたいという人は、以下の記事で解説しているのでぜひ読んでみてください。
- 精度向上:SI-SNRi 13.2dB → 15.3dB(LSTMより +2.1dB)
- 軽量化:パラメータ数 23.6M → 5.1M(約 1/5)
- 高速化:CPU処理時間 4.3ms → 0.4ms(10倍以上)
2. TasNetの問題点
元のTasNetはエンコーダ・デコーダ構造は優れていましたが、分離モジュールにLSTMを使っていたことが3つのボトルネックになっていました。
2.1 セグメント長を短くできない
音声を短いセグメントに分けるほど分離精度が上がることが実験的にわかっています。
直感的な理由は、短いセグメントは単音に近いからです。40msの区間には複数の音素が混在しますが、 2msの区間はほぼ1つの音素しか含まれません。短い方がマスク推定が簡単になります。
しかし、セグメントを短くすると時系列が長くなるといった問題が起こります。
LSTMについて詳しい内容を知りたい人は各自で調べてほしいのですが、 LSTMは長すぎる時系列が苦手です。勾配消失・爆発が起きやすくなり、学習が不安定になります。 このため、LSTMのままでは「短いセグメント=高精度」という恩恵を受けられませんでした。
2.2 パラメータ数が膨大
なぜLSTMはパラメータが多いのか
LSTMの1層には4つのゲートがあり、それぞれに重み行列が必要です。 隠れ次元を、入力次元を とすると、1層のパラメータ数はおよそ
が大きくなるとに比例してパラメータが増えるため、 深くするほど急激に膨れ上がります。
| モデル | パラメータ数 |
|---|---|
| BLSTM-TasNet | 23.6M〜32.0M |
| Conv-TasNet | 5.1M |
スマートフォンや補聴器などへの搭載を考えると、軽量化は必須です。
2.3 入力の開始点に依存した不安定性
LSTMの逐次処理と誤差累積
LSTMは時刻の処理に必ず時刻の出力が必要です。
これが逐次処理です。図で表すと以下のようになります。
x(1)→[LSTM]→h(1)→[LSTM]→h(2)→[LSTM]→h(3)→ ... →h(2000) ↑ ↑ ↑ h(0)を使う h(1)を使う h(2)を使う
※ フレーム1が終わらないとフレーム2が始められないここで重要なのは、初期状態に何を使うかという問題です。
通常、最初の隠れ状態はゼロベクトルで初期化されます。 しかしこれは音声が必ず先頭から始まるという暗黙の仮定です。
開始点をずらすと何が起きるか
現実の音声処理では、どのサンプルから処理を始めるかは任意です。
元の波形: [===========音声============] ↑ サンプル0から開始 → 安定
開始をずらす: [=========音声============] ↑ サンプル5から開始 → LSTMの初期状態がずれるLSTMはゼロ初期化の隠れ状態から「文脈を積み上げていく」ため、どこから始めるかで文脈の積み上げ方が変わってしまいます。
さらに逐次処理なので、序盤に生じたわずかなずれが後続フレーム全体に波及してしまいます。
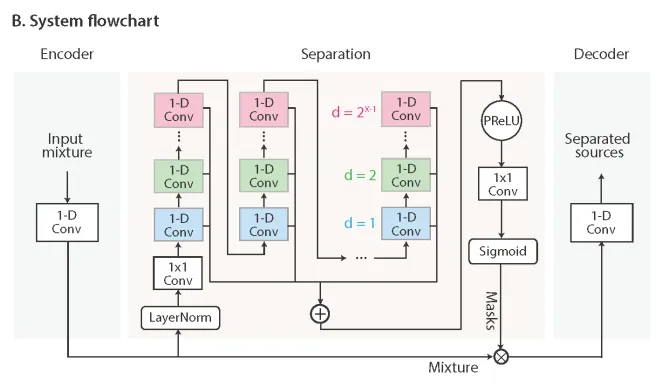
3. Conv-TasNetのアーキテクチャ
基本のEncoder–Mask–Decoder構造はTasNetと同じです。変わったのはSeparation, 分離モジュールのみです。
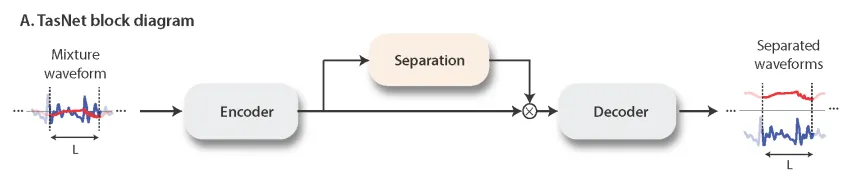
3.1 TCN(Temporal Convolutional Network)の全体像
TCNは次のような構造をしています。
論文の最良構成では X=8, R=3、つまり合計 24個のブロックが積み重なります。
LSTMの問題は「過去から順番に処理するしかない」ことでした。 TCNはこれを解決するために畳み込みだけで時系列の文脈を捉える仕組みです。
しかしここで素朴な疑問が生まれます。
畳み込みはカーネルサイズ分しか見えないのに、どうやって遠い過去の情報を使うの?
LSTMは理論上「過去すべて」を参照できますが、実際には遠い過去の情報は勾配消失によって薄れていきます。
Dilated Convolution は 「どこまで確実に参照するか」を明示的に設計できます。受容野の範囲内であれば、勾配が確実に届きます。
これを解決するのがDilated Convolutionです。
3.2 Dilated Convolution(拡張畳み込み)
畳み込みの直感的理解
まず畳み込みとはなんでしょうか?
音声データは以下のように時刻ごとの数字の列として表現できます。
時刻: 1 2 3 4 5 6 7 8音声: 0.1 0.3 0.8 0.6 0.2 0.5 0.9 0.4畳み込みは、この数字列に小さな窓をスライドさせながら特徴を抽出する操作のことです。
時刻: 1 2 3 4 5 6 7 8 [ 窓 ] [ 窓 ] [ 窓 ] [ 窓 ]窓の中の数字をニューラルネットが学習した重みで組み合わせてこの時刻の音声はこういう特徴だという情報を出力します。
ここで、窓のサイズのことをカーネルサイズ、1回の計算で参照できる範囲のことを受容野といいます。
通常の畳み込み
カーネルサイズの畳み込みは、受容野は3時刻分しかありません。
例えば時刻5の特徴を計算するとき、以下のようになります。
時刻: 1 2 3 4 5 6 7 8 [ 窓 ] 4 5 6 ← この3点しか参照できない音源分離ではもっと遠い過去の情報も必要です。たとえば「さっきAさんはこういう声を出していた」という手がかりが分離に役立ちます。
受容野を広げるには窓(カーネル)を大きくすればいいのですが、そうするとその分だけ学習パラメータが増えてモデルが重くなってしまいます。
Dilated Convolution (飛ばし読み)
窓(カーネル)のサイズはそのままで、一定間隔おきに点を選んで参照するのがDilated Convolutionのアイデアです。
この飛ばし幅のことをdilationといいます。
【dilation=1:飛ばしなし(普通の畳み込み)】
時刻: 1 2 3 4 5 6 7 8 ↑ ↑ ↑ 隣り合う3点を参照(受容野=3)
【dilation=2:1個飛ばし】
時刻: 1 2 3 4 5 6 7 8 ↑ ↑ ↑ 1個おきに3点を参照(受容野=5)
【dilation=4:3個飛ばし】
時刻: 1 2 3 4 5 6 7 8 9 ↑ ↑ ↑ 3個おきに3点を参照(受容野=9)参照する点の数(=パラメータ数)は常に3点のまま、見える範囲だけが広がっていく。 これがDilated Convolutionの核心です。
dilationを倍々に増やしていく
Conv-TasNetではdilationを1>2>4>8>16>32>64>128と倍々に増やしながら8つのブロックを積み重ねます。
ブロック1(dilation=1) :受容野 = 3時刻分ブロック2(dilation=2) :受容野 = 5時刻分ブロック3(dilation=4) :受容野 = 9時刻分ブロック4(dilation=8) :受容野 = 17時刻分ブロック5(dilation=16) :受容野 = 33時刻分ブロック6(dilation=32) :受容野 = 65時刻分ブロック7(dilation=64) :受容野 = 129時刻分ブロック8(dilation=128):受容野 = 257時刻分
8ブロック積み重ねると合計の受容野 ≈ 511時刻分 ≈ 約1.5秒分ブロックを重ねるごとに「見える範囲」が広がっていくイメージです。
ブロック1:[● ● ● ] 近くの細かい変化ブロック2:[● ● ● ]ブロック3:[● ● ● ]ブロック4:[● ● ● ]ブロック5:[● ● ●] :ブロック8:[● ● ●] ← 約1.5秒分近くを精密に見るブロックと、遠くで大まかに見るブロックが役割分担しているのがわかると思います。
191ms先の情報まで参照できれば、語の区切りやイントネーションといった音声の長期的なパターンを十分カバーできます。
LSTMは理論上「過去すべて」を参照できますが、実際には遠い過去の情報は勾配消失によって薄れていきます。
Dilated Convolution は 「どこまで確実に参照するか」を明示的に設計できます。受容野の範囲内であれば、勾配が確実に届きます。
3.3 Depthwise Separable Convolution
まず「チャンネル」とは
ここで新しい概念が登場します。音声の特徴は一つの数字列ではなく、複数のチャンネルとして表現されるということです。
チャンネル1(高音域の特徴):0.1 0.3 0.8 0.6 ...チャンネル2(低音域の特徴):0.5 0.2 0.4 0.9 ...チャンネル3(リズムの特徴):0.8 0.8 0.1 0.1 ... :チャンネルN(別の特徴) :0.3 0.7 0.2 0.5 ...Conv-TasNetでは512チャンネル分の情報を同時に処理しています。
通常の畳み込みはこのとき「時間方向の処理(どの時刻を見るか)」と「チャンネル間の混合」を同時にやっています。
パラメータ数は入力チャンネル数 、出力チャンネル数 、カーネルサイズ として、
2段階に分けることで削減する
Depthwise Separable Convolutionは「時間方向の処理」と「チャンネル間の混合処理」の操作を別々のステップに分けます。
Step 1: Depthwise Conv(時間方向だけ処理)
各チャンネルを独立にカーネルサイズ で畳み込みます。
チャンネル1 → [時間方向の畳み込みP=3] → チャンネル1の出力 チャンネル2 → [時間方向の畳み込みP=3] → チャンネル2の出力 : : チャンネル128→ [時間方向の畳み込みP=3] → チャンネル128の出力
Step 2: Pointwise Conv(チャンネル間だけ混合)
今度は時間方向の処理はせず、各時刻でチャンネル間の情報だけを混ぜる(カーネルサイズ1の畳み込み)。
各時刻において:[ch1, ch2, ch3, ..., ch128] → [出力ch1, 出力ch2, ..., 出力ch512] ↑チャンネル間を混ぜるだけ、時間方向の処理はしないここでパラメータの削減効果を見てみましょう。
| 計算 | パラメータ数 | |
|---|---|---|
| 通常の畳み込み | 196,608 | |
| Depthwise Sep. | 65,920 | |
| 削減率 | 約3分の1 |
「チャンネルを独立に畳み込む(時間方向の特徴抽出)」と「チャンネル間を混合する(情報統合)」を分離しても、ニューラルネットが学習でそれぞれの役割を分担して学んでくれます。
画像認識の MobileNet や Xception でも同じ手法が使われており、精度を保ちながら軽量化できることが実証されています。
3.4 各ブロックの詳細構造
1つの畳み込みブロックの中身をここで説明します。
入力 x(Bチャンネル、T時刻) │ ├──────────────────────────────────────────┐ │ │ 入力をそのまま保存 ↓ │[1×1-Conv] チャンネルをBからHへ拡張 │[PReLU] 活性化関数 │[Norm] 正規化 │ ↓ │[D-Conv] Dilated畳み込み(dilation=d) │[PReLU] │[Norm] │ ↓ │ ├─────────────────────┐ │ ↓ ↓ │[1×1-Conv] [1×1-Conv] │(Residual path) (Skip path) │ ↓ ↓ │ +←──────────────────────────────────────── ┘ │ 入力xを足す ↓次のブロックへ 最終的なマスク生成に蓄積2つの出力経路があります。
Residual(残差接続):元の入力 をそのまま足して次ブロックへ渡します。勾配消失を防ぎ、24層積み重ねても学習が安定します。
Skip connection:各ブロックの中間特徴をすべて蓄積し、最後にまとめてマスクを生成します。浅いブロックも深いブロックも平等にマスク生成に貢献します。
PReLU は ReLU の「負の値を完全に0にする」問題を改善した活性化関数です。
は学習で決まるパラメータです。負の領域でも少し情報を残せるので、ReLU より表現力が高くなります。
3.5 正規化:gLNとcLN
Conv-TasNetでは用途に応じて2種類の正規化を使い分けます。
gLN(Global Layer Norm):オフライン処理向け
音声全体(全時刻のデータ)を使って平均と分散を計算し、正規化します。
精度は高いですが、未来のデータが必要なのでリアルタイム処理には不向きです。
cLN(Cumulative Layer Norm):リアルタイム処理向け
その時刻までに届いたデータのみを使って平均と分散を計算する手法です。
精度はgLNより約4~5dBほど低くなりますが、補聴器や通話機器への搭載にはリアルタイム動作が必須なので、この使い分けが重要になります。
4. エンコーダ設計の再検討
TasNet のエンコーダは ReLU で非負制約を課していましたが、Conv-TasNet ではこれを外す実験をしています。
| エンコーダ | マスク | SI-SNRi |
|---|---|---|
| Linear(制約なし) | Sigmoid | 15.3 dB(最良) |
| ReLU | Softmax | 14.0 dB |
| Pseudo-inverse | Sigmoid | 9.4 dB(最悪) |
Pseudo-inverse autoencoder は「エンコーダとデコーダが完璧な逆演算になるよう制約する」手法です。完璧な再構成を保証するために自由度を大幅に制限した結果、分離に必要な表現力が失われました。
「エンコーダが混合信号を完璧に再構成できること」は分離性能に必須ではない。
過完備(次元数が豊富)な表現さえあれば、マスクで各話者を分離できる。
5. 実験結果の要約
5.1 何を評価したか
音源分離の精度を測る指標として主に2つを使っています。
- SI-SNRi:分離後の音声がどれだけクリアになったかを示す値です。大きいほど良いです。
- SDRi:SI-SNRiに近い別の指標です。これも大きいほど良いです。
加えて人間に聞いてもらって品質を評価する手法(MOS)と、自動的に音質を測るスコア(PESQ)も使用しています。
5.2 エンコーダの設計について
エンコーダの出力に「マイナスの値を許すか・許さないか」を比較した実験です。
結論は**「マイナスの値を許す線形エンコーダ+Sigmoidマスクが最も良い」**。
直感に反して、エンコーダが入力を完璧に再現できる設計(Pseudo-inverse)は最も性能が悪かった。「完璧な再現性」よりも「過完備な表現(情報を冗長に持つこと)」の方が分離に役立つという発見。
5.2 ハイパーパラメータの影響
色々な設定を変えて実験した結果のまとめ。
セグメント長は短いほど良い
エンコーダの窓サイズを短くするほど精度が上がった。最良はわずか2ms。LSTMではこんなに短くできなかったので、TCNに変えた恩恵が大きい。
受容野は広いほど良い
遠くまで参照できるほど精度が上がった。音声の長期的なパターンが分離に重要だということ。
深いほど良い
受容野が同じでも、ブロック数が多い(深い)方が精度が高かった。
因果モード(リアルタイム)は精度が落ちる
未来の情報を使えない分、約4〜5dB低くなる。これはある程度仕方ない。
5.3 先行手法との比較
WSJ0-2mix(2話者分離)での比較をした結果です。
手法 パラメータ数 SI-SNRi─────────────────────────────────────────────DPCL++ 13.6M 10.8 dBBLSTM-TasNet 23.6M 13.2 dBConv-TasNet(非因果) 5.1M 15.3 dB ← 最良─────────────────────────────────────────────理想マスク IRM − 12.2 dB理想マスク IBM − 13.0 dB理想マスク WFM − 13.4 dB ← これも超えたここで注目すべき点が2つあります。
- パラメータ数が最小(5.1M)なのに精度が最高
- 「理想マスク」をすべて上回った
理想マスクとは「正解の音声が分かっている状態で計算した理論上の上限」のこと。 それを超えたということは、Conv-TasNetが時間領域で直接処理することでSTFTベースの手法では原理的に超えられない壁を突破したことを意味します。
3話者分離(WSJ0-3mix)でも同様に全手法を大幅に上回ることがわかりました。
5.4 人間による主観評価
40人の被験者に聞いてもらって音質を1〜5点で評価した実験です。
手法 MOS(人間の評価) PESQ(自動評価)──────────────────────────────────────────────クリーン音声 4.23 4.5Conv-TasNet 4.03 3.24 ← 人間評価は高いIRM(理想マスク) 3.51 3.74 ← 自動評価は高いここに面白い逆転現象がありました。
- 自動評価(PESQ)ではIRMの方が高い
- 人間の評価(MOS)ではConv-TasNetの方が有意に高い(p < 1e-16)
なぜこうなるかというと、PESQは周波数領域の振幅を基準に評価する設計になっているため、 時間領域で直接処理するConv-TasNetを不当に低く評価してしまうのです。
人間の耳には確実にConv-TasNetの方がきれいに聞こえているということです。
5.5 処理速度
続いて処理速度に関しては、LSTMを利用した手法と比べて10倍以上速い結果が得られました。
5.6 開始点の安定性
入力波形の開始サンプルをずらしたときの精度変化を検証した実験です。
LSTMは開始点を少しずらすだけでSDRiが7dBから14dBの間で激しく変動していた一方で、 Conv-TasNetは開始点を変えても精度がほぼ変わらず安定していました。
理由は前の記事でも述べましたが、畳み込みは各フレームを独立に処理するので、あるフレームの失敗が次のフレームに伝播しないということです。
5.7 学習されたフィルタの分析
最後にエンコーダが学習した512個のフィルタを分析した結果、2つの興味深い性質が見つかりました。
60%以上のフィルタが1kHz以下の低周波数にチューニングされている
同じ周波数でも異なる位相を持つフィルタが複数ある
STFTは位相情報を正弦波・余弦波の2種類しか表現できませんが、 Conv-TasNetのフィルタは様々な位相を陽に表現しています。 これがSTFTベースの手法を超えられた主な理由だと考察されています。
全体のまとめ
Conv-TasNetの強みをひとことで言うと、位相と振幅を分けずに時間領域で直接処理することで、 STFTベースの手法が原理的に超えられなかった限界を突破したことです。 その上でTCNによって軽量・高速・安定という実用面の課題も同時に解決することができました。
参考文献
Luo, Y., & Mesgarani, N. (2019). Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing. arXiv:1809.07454
Luo, Y., & Mesgarani, N. (2018). TasNet: Time-Domain Audio Separation Network for Real-Time, Single-Channel Speech Separation. ICASSP 2018. arXiv:1711.00541