1. はじめに
Part3はシリーズ最終回です。まず前2回のポイントを振り返りましょう。
Part1(背景・問題設定)のポイント
- TFドメインモデルは残響対策に有利
- 当時最強のTF-GridNetはRNN(ローカル)+ Self-Attention(グローバル)で実現していた
- しかしRNNは逐次処理しかできず、Transformerの恩恵(並列化・スケーリング)を受けられない
- TF-Locoformerの解決策:FFNをConvSwiGLUに変えてローカル性を担保し、RNNを廃止
Part2(アーキテクチャ)のポイント
- STFTで音声を時間×周波数の2次元マップに変換
- Dual-Path構造:Intra(周波数方向)とInter(時間方向)を交互に処理
- 各ブロックはマカロン構造:ConvSwiGLU → Self-Attention → ConvSwiGLU
今回のPart3では「TF-Locoformerの核心技術」に踏み込みます:
- ConvSwiGLU:どうやってローカル性を組み込んだのか
- RMSGroupNorm:なぜ通常のLayerNormを使わないのか
- 実験結果:TF-GridNetに対してどれだけ性能が改善されたのか
2. ConvSwiGLUの技術詳細
2.1 標準FFNの復習と限界
まず、標準的なFFN(Feed-Forward Network)を確認しておきましょう。
TransformerのFFNは「2層の全結合層+活性化関数」です:
行列の形を追うと:
入力 x ∈ ℝ^{N × D} ↓ W₁ ∈ ℝ^{D × 4D}(次元を4倍に拡張) ↓ ReLU ↓ W₂ ∈ ℝ^{4D × D}(次元を元に戻す)出力 ∈ ℝ^{N × D}ReLU(Rectified Linear Unit)はで負の値を0にカットする活性化関数です。
このFFNは位置ごとに独立に適用されます。つまり位置 i の出力は位置 i の入力だけで決まり、隣の位置 i-1 や i+1 は一切参照しません。
位置1: x₁ → [FFN] → x'₁ ← x₂, x₃, ... は参照しない位置2: x₂ → [FFN] → x'₂ ← x₁, x₃, ... は参照しない位置3: x₃ → [FFN] → x'₃ ← x₁, x₂, ... は参照しないこれが標準FFNの限界です。音声スペクトログラムには「隣り合うビンやフレームは似た値を取りやすい」という局所的な構造がありますが、標準FFNはその構造を一切活用できません。
2.2 GLU(Gated Linear Unit)とは
ConvSwiGLUを理解するために、まずGLU(Gated Linear Unit)から始めます。
GLUは「重要な情報を選択的に通過させる」ゲート機構です(Dauphin et al., 2016):
- 第1項
σ(W₁x)がゲート:はシグモイド関数(:どんな値も0〜1に押し込む関数)で「どれだけ通過させるか」を決める - 第2項
W₂xが内容:通過させる情報そのもの ⊙が要素積:ゲートを通過した情報だけを出力
【GLUのイメージ】
入力 x ─────────┬────────────────────────── │ │ ↓ W₁ ↓ W₂ σ(W₁x) W₂x [0〜1のゲート] [内容] │ │ └──────── ⊙ ───────────────┘ (要素積) ↓ GLU(x) = σ(W₁x) ⊙ W₂xTasNetの記事でも出てきた「ゲーテッドエンコーダ」と同じ発想です。
ReLU(max(0, x))は値の正負だけで機械的に通過/遮断を決めます。「この情報は重要だから通す」という判断はできません。
GLUは σ(W₁x) という別のネットワークが「どの情報を通過させるか」を学習します。つまり重要な情報を動的に選んで通過させることができます。
この仕組みにより勾配が流れやすくなり、学習がより安定します。
2.3 SwiGLU:SwishとGLUの組み合わせ
SwiGLUは2020年にNoam Shazeerによって提案されたGLUの改良版です(「GLU Variants Improve Transformers」)。
ゲート部分のシグモイド関数 σ をSwish関数に置き換えたものです:
Swishはシグモイドと入力値の掛け算で、グラフで見ると次のような形になります:
【Swish関数のグラフ(概略)】
y ↑ │ / │ / │ / --│--------/---------→ z │ / │ / │ ← ゼロ付近で少し負の値を持つ(ReLUとの違い)Swishの重要な性質:
- 正の領域では
y ≈ z(ReLUとほぼ同じ) - ゼロ付近では少しマイナスの値を持つ(ReLUの不連続性がない)
- 微分が連続で滑らか:勾配がスムーズに流れ、学習が安定
SwiGLUはGPT-4・LLaMa・PaLMなど現代の大規模言語モデルで広く採用されており、通常のFFNより一貫して性能が良いことが実験的に確認されています。
ただし、SwiGLUもやはり位置ごとに独立した変換であり、局所的な位置間の相関はまだ捉えられません。
2.4 ConvSwiGLU:Depthwise Convを追加する
TF-Locoformerの核心がここです。SwiGLUの W₂x のパスの線形変換を、Depthwise Conv1D(カーネルサイズ K)に置き換えます:
これをステップごとに丁寧に見ていきましょう。
Step 1:次元の拡張と分割
入力 x ∈ ℝ^{N × D} ↓ 線形変換 W_up(D → 4D)x' ∈ ℝ^{N × 4D} ↓ チャンネル方向に半分ずつ分割g ∈ ℝ^{N × 2D} (Gate用)v ∈ ℝ^{N × 2D} (Value用)Step 2:各ブランチの処理(ここが従来との違い)
gブランチ(ゲート):
g ∈ ℝ^{N × 2D} ↓ Swish活性化Swish(g) ∈ ℝ^{N × 2D}vブランチ(内容):
v ∈ ℝ^{N × 2D} ↓ Depthwise Conv1D(カーネルサイズ K=4)← ここが核心Conv(v) ∈ ℝ^{N × 2D}Depthwise Conv1Dとは「各チャンネルを独立に1次元畳み込みする」操作です:
【Depthwise Conv1D(K=4)の動作イメージ】
系列方向(例:周波数方向 f1〜fN):
チャンネル d のカーネル:[w_{d,0}, w_{d,1}, w_{d,2}, w_{d,3}]
位置 i の出力: v'_{i,d} = w_{d,0}×v_{i,d} + w_{d,1}×v_{i-1,d} + w_{d,2}×v_{i-2,d} + w_{d,3}×v_{i-3,d} ↑自分 ↑1つ前 ↑2つ前 ↑3つ前
→ 近傍4ビン(またはフレーム)の情報を参照して新しい値を計算「Depthwise」とはチャンネル間の情報を混ぜずに、各チャンネルで独立に畳み込むことです:
チャンネル1:[v₁,₁, v₂,₁, v₃,₁, ...]→ Conv → [v'₁,₁, v'₂,₁, v'₃,₁, ...]チャンネル2:[v₁,₂, v₂,₂, v₃,₂, ...]→ Conv → [v'₁,₂, v'₂,₂, v'₃,₂, ...]...(各チャンネルが独立したカーネル w_{d} を持つ)パラメータ数は 2D × K(チャンネル数 × カーネルサイズ)のみ。通常の1D-Convの (2D)² × K と比べて大幅に少なく、軽量に実現できます。
Step 3:ゲーティングと出力射影
h = Swish(g) ⊙ DepthwiseConv1D(v, K) ∈ ℝ^{N × 2D} ↓ 線形変換 W_down(2D → D)出力 ∈ ℝ^{N × D}全ステップをまとめると:
【ConvSwiGLU全体のデータフロー】
x ∈ ℝ^{N × D} ↓ W_up(D → 4D) ↓ split ├── g(2D) → Swish(g) ← 0〜1のゲート └── v(2D) → DepthwiseConv1D(v, K) ← 近傍K個の情報を取り込む ↓ 要素積 Swish(g) ⊙ Conv(v) ↓ W_down(2D → D)出力 ∈ ℝ^{N × D}
「Convが取り込んだ局所情報を、Swishゲートで重要な部分だけ通過させる」2.5 K=4が最適な理由:カーネルサイズとローカル性
カーネルサイズKはConvSwiGLUの「ローカル性の半径」を決める重要なパラメータです。
K=1(純粋な線形変換): Conv1D(v, K=1) = W × v ← 各位置が独立。SwiGLUと等価。ローカル性なし。
K=4(デフォルト): 各位置が近傍4つを参照 ← 適度なローカル性。実験で最良。
K=8: 各位置が近傍8つを参照 ← 窓が大きすぎると性能が低下。Intra-blockで周波数方向に適用する場合を考えましょう。
STFTの周波数解像度が約50Hzとすると:
- K=4 → 参照範囲 = 200Hz
- 人の声のフォルマント(声の共鳴周波数)の幅は100〜300Hz程度
K=4の参照範囲がフォルマントの幅とほぼ一致しており、「フォルマントの滑らかな山」を捉えるのにちょうどよいサイズだと考えられます。
K=8以上は無関係なビンも混ぜてしまう恐れがあり、性能が低下します。
論文のアブレーション実験より、K値ごとの性能をまとめます。WSJ0-2mixとは2話者分離の標準ベンチマークで、WHAMR!と異なり残響・ノイズを含まないクリーンな音声データセットです:
| カーネルサイズ K | SI-SNRi(dB) | 備考 |
|---|---|---|
| K=1(線形変換のみ) | 22.8 | ローカル性なし、SwiGLUと等価 |
| K=3 | 23.5 | 良好 |
| K=4 | 23.6 | 最良(デフォルト採用) |
| K=8 | 23.2 | やや劣化 |
K=1(ローカル性なし)に比べてK=4(ローカル性あり)は +0.8dB の改善。これがConvSwiGLUの局所畳み込みが性能に与える効果です。
2.6 ConvSwiGLU vs RNN:何が変わったのか
ここで改めてPart1の問いに戻りましょう。TF-GridNetのRNNとTF-LocoformerのConvSwiGLUを比べます。
| 性質 | RNN | ConvSwiGLU(K=4) |
|---|---|---|
| ローカル性 | 構造的に近傍を重視(距離に応じて情報が薄れる) | K個の近傍を明示的に参照 |
| 並列処理 | 不可(逐次処理が必須) | 完全に並列 |
| 参照範囲 | 原理上無限(実際は遠いほど薄れる) | 厳密に K 個に限定 |
| 計算コスト | O(T × d²)(逐次のため追加コスト) | O(T × d × K)(Conv の計算コスト) |
RNNは「逐次処理によって自然に生まれる近傍バイアス」を利用していましたが、それが並列化不可能という致命的な欠点でした。
ConvSwiGLUは「局所畳み込みによって明示的に近傍バイアスを組み込む」ことで、RNNと同等のローカル性を並列に実現しています。
3. RMSGroupNormの技術詳細
3.1 なぜ正規化が必要か(復習)
深いネットワークでは、層を通るたびに各ニューロンの出力値の分布がずれていく「内部共変量シフト」が起きます。
入力層の出力:平均 0.0、分散 1.01層目の出力:平均 0.3、分散 1.8 ← 少しずれた2層目の出力:平均 0.8、分散 4.2 ← さらにずれた3層目の出力:平均-1.5、分散 9.3 ← 大きくずれたこの分布のずれが学習を不安定にします。正規化はこれを防ぎ、学習を安定させます。
3.2 LayerNormとRMSNorm
まず最もよく使われるLayerNormを確認します。
LayerNormは各サンプルのD次元全体にわたって正規化します:
- :D次元にわたる平均
- :標準偏差
- :学習可能なスケールとシフト
- :ゼロ除算防止の小定数(例:1e-8)
TasNetやConv-TasNetの記事でも登場した正規化手法です。
RMSNormはLayerNormを簡略化したものです(Zhang & Sennrich, 2019):
LayerNormとの違いを表にまとめます:
| 性質 | LayerNorm | RMSNorm |
|---|---|---|
| 平均を引く(中心化) | あり(x - μ) | なし |
| 分散(または二乗平均)で割る | あり(σ) | あり(RMS) |
| 学習パラメータ | γ(スケール)とβ(シフト) | γ(スケール)のみ |
| 計算コスト | やや重い | 約7〜15%軽量 |
LayerNormの「平均を引く(中心化)」という処理は、実は学習可能なスケール γ とシフト β によってほぼ打ち消されることが多いです。
つまり、「平均を引く」ために費やす計算コストのわりに、モデルが実際に活用していないケースが多いのです。RMSNormはこの「不要な中心化」を省略することで、計算を軽くしながら性能は同等を保ちます。
LLaMa・Gemma・Mixtralなど現代の大規模言語モデルのほとんどがRMSNormを採用しています。
3.3 GroupNormとは
GroupNormはコンピュータビジョン(CV)の分野で提案された正規化手法です(Wu & He, 2018)。
LayerNormがD次元全体を一括で正規化するのに対し、GroupNormはD次元をG個のグループに分けて、各グループ内で独立に正規化します。
【LayerNormとGroupNormの比較(D=8次元、G=4グループ)】
D次元:d₁ d₂ d₃ d₄ d₅ d₆ d₇ d₈
LayerNorm: ←── 全D次元で μ, σ を計算して一括正規化 ──→
GroupNorm(G=4): [d₁, d₂] [d₃, d₄] [d₅, d₆] [d₇, d₈] ↑グループ1 ↑グループ2 ↑グループ3 ↑グループ4 各グループ内で独立に正規化GroupNormを音声分離に使う意義:
話者分離タスクでは、特徴次元のグループが「話者Aに関する情報」と「話者Bに関する情報」を担当することが期待されます。
【音声分離での特徴次元の役割分担イメージ】
D=256次元: d₁〜d₆₄ → 話者Aの周波数特性に関する情報 d₆₅〜d₁₂₈ → 話者Bの周波数特性に関する情報 d₁₂₉〜d₁₉₂→ 残響パターンに関する情報 d₁₉₃〜d₂₅₆→ ノイズパターンに関する情報この場合、全次元で一括正規化すると話者A・B・残響・ノイズの情報が混ざってしまいます。グループごとに正規化することで、各グループが担当する情報を独立に保ちやすくなります。
ただし、これは学習によって自然に形成される役割分担であり、設計で強制するものではありません。GroupNormがその形成を「誘導する」という効果です。
3.4 RMSGroupNorm:2つのアイデアを組み合わせる
TF-Locoformerが採用するRMSGroupNormは、GroupNormの「グループに分けて正規化する」考え方と、RMSNormの「中心化なしのRMS正規化」を組み合わせたものです:
「D次元をG個のグループに分けて、各グループ内でRMSNormを適用する」
各グループのサイズは D/G(例:D=256, G=4 → 各グループ64次元)。
【RMSGroupNorm(G=4, D=8)の処理イメージ】
D次元:d₁ d₂ d₃ d₄ d₅ d₆ d₇ d₈
グループ1: [d₁, d₂] → RMS₁ = √((d₁²+d₂²)/2) → γ₁ × d₁/RMS₁, γ₂ × d₂/RMS₁
グループ2: [d₃, d₄] → RMS₂ = √((d₃²+d₄²)/2) → γ₃ × d₃/RMS₂, γ₄ × d₄/RMS₂
グループ3: [d₅, d₆] → RMS₃ = ...グループ4: [d₇, d₈] → RMS₄ = ...
※ 各グループが独立に正規化されるため、グループ間の情報は混ざらないRMSGroupNormのメリット整理:
| メリット | 理由 |
|---|---|
| グループ分離による話者情報の保持 | 各グループが担当する情報(話者特性など)を混ぜずに正規化 |
| RMSNormによる軽量化 | 平均計算とβパラメータが不要 |
| 学習の安定化 | LayerNorm同様、内部共変量シフトを抑制 |
論文では G = D / 64 をデフォルトとしています(例:D=256 → G=4)。
各グループが64次元を担当することで、グループ内に十分な統計量が得られます。グループが小さすぎると統計が不安定になり、大きすぎると(G=1のとき = RMSNorm)話者情報が混ざる恐れがあります。
4. 実験結果
4.1 評価設定
データセット:WHAMR!
WHAMR!(WHAM! with Reverb)は、2人が同時に話す混合音声に残響とノイズを加えたデータセットです。
【WHAMR!の混合音声の構成】
混合音声 = 話者Aの直接音 + 話者Aの残響(80〜数百ms遅延した反射音) + 話者Bの直接音 + 話者Bの残響 + 環境ノイズ(カフェ、道路など)残響が含まれることで、Conv-TasNetのような短い窓のモデルでは対処が難しく、TFドメインモデルの有利さが現れやすいデータセットです。Part1で説明した「残響問題」の難しさが測れるベンチマークです。
評価指標:SI-SNRi
SI-SNRi(Scale-Invariant Signal-to-Noise Ratio improvement)は分離後の音声がどれだけ改善されたかをdBで表します。値が大きいほど良いです。
SI-SNRi = SI-SNR(分離後)− SI-SNR(混合音のまま)
意味の目安: 0 dB :分離していないのと同じ 10 dB :混合音よりかなりきれいに聞こえる 20 dB :非常にきれいな分離(プロレベルに近い)「improvement(改善量)」を見ることで、モデルが入力に対してどれだけ貢献したかがわかります。
4.2 先行手法との比較
WHAMR!(2話者分離)における主要な結果です(論文より)。なお(S)はSmall(小規模版)、(M)はMedium(中規模版)を表し、モデルのパラメータ数が異なります:
| モデル | RNNあり | SI-SNRi(dB) |
|---|---|---|
| Conv-TasNet | なし | 9.0 |
| TF-GridNet-Lite | あり | 16.9 |
| TF-GridNet | あり | 18.5 |
| TF-Locoformer (S) | なし | 17.1 |
| TF-Locoformer (M) | なし | 18.8 |
注目すべきポイントが2つあります。
ポイント①:TF-Locoformer (M) がRNNなしでTF-GridNetを上回った
TF-GridNet(RNNあり):18.5 dB TF-Locoformer (M)(RNNなし):18.8 dB
RNNなしでRNNありモデルを超えた。これがTF-Locoformerの最大の意義です。
ポイント②:軽量版 (S) でもTF-GridNet-Liteを上回った
TF-GridNet-Lite(RNNあり):16.9 dB TF-Locoformer (S)(RNNなし):17.1 dB
同程度のモデルサイズでも、RNNなしの設計がより高い性能を発揮しています。
4.3 アブレーション研究:マカロン構造の効果
「前後どちらのConvSwiGLUが重要か」を検証したアブレーション実験です(WSJ0-2mixデータセット。前節と同じクリーンな2話者分離ベンチマーク):
| 設定 | SI-SNRi(dB) | 変化 |
|---|---|---|
| フルモデル(前FFN + Attention + 後FFN) | 23.6 | − |
| 前ConvSwiGLUを削除(Attention + 後FFN) | 22.8 | −0.8 dB |
| 後ConvSwiGLUを削除(前FFN + Attention) | 22.9 | −0.7 dB |
| 標準Transformer(FFN1個のみ) | 22.5 | −1.1 dB |
前後どちらのConvSwiGLUを削除しても性能が低下します。マカロン構造の2つのConvSwiGLUが両方とも必要であることがわかります。
4.4 アブレーション研究:K値の効果
「畳み込みのカーネルサイズ K が性能にどう影響するか」の実験です:
| カーネルサイズ K | SI-SNRi(dB) | 解釈 |
|---|---|---|
| K=1(線形変換のみ) | 22.8 | ローカル性なし(SwiGLUと等価) |
| K=3 | 23.5 | 近傍3個を参照 |
| K=4 | 23.6 | 近傍4個を参照(デフォルト) |
| K=8 | 23.2 | 近傍8個を参照(やや劣化) |
2つのアブレーション実験から、TF-Locoformerの設計原理が確認されます。
ローカル性は不可欠:K=1(ローカル性なし)に比べてK=4(ローカル性あり)で+0.8dB。ConvSwiGLUの局所畳み込みがRNNの代替として機能している証拠
適切な窓サイズ:K=4が最適。小さすぎると局所情報が不十分、大きすぎると無関係な情報が混入
マカロン構造が重要:前後どちらのFFNも削除で性能低下。Attentionの前後でローカルな処理をすることに意味がある
4.5 並列化による計算速度の改善
TF-GridNetとTF-Locoformerの計算特性を比較します。
【TF-GridNet(RNNあり)の計算】
RNNの更新:h(t) = f(h(t-1), x(t))
時刻1の処理が終わらないと時刻2が始められない→ T フレームを処理するには必ず T ステップを逐次実行→ どんなに多くのGPUがあっても並列化できない
【TF-Locoformer(RNNなし)の計算】
Self-Attention:全ペアのスコアを行列積で一括計算ConvSwiGLU:全位置の畳み込みを並列に計算
→ T フレームを1ステップで同時処理→ GPUの並列性を最大限に活用できるこの並列性の差が、学習速度と推論速度の大幅な改善をもたらします。
さらに、RNNを廃止したことでTransformerエコシステムのフルサポートが受けられます:
- FlashAttention:メモリ効率の良いAttention実装
- 量子化・枝刈り:モデル軽量化手法
- 分散学習フレームワーク:大規模データでの学習
これらはすべてRNNには適用できないか、適用しにくいものです。TF-Locoformerへの切り替えは、「今より高い性能」だけでなく「将来的なスケーリングの扉を開く」ことを意味しています。
5. 3部作のまとめ
3部にわたってTF-Locoformerを解説してきました。最後に全体を振り返ります。
なぜTF-Locoformerが必要だったか(Part1)
音声分離には残響に強いTFドメインが有利。しかし当時最強のTF-GridNetはRNNを使っており、並列化できなかった。
問題: TFドメインには「ローカルな情報(近傍の相関)」と 「グローバルな情報(大域的パターン)」の両方が必要 ↓ RNN(ローカル担当)+ Self-Attention(グローバル担当)で解決したが RNNの逐次処理が並列化の障害になっていたアーキテクチャの構造(Part2)
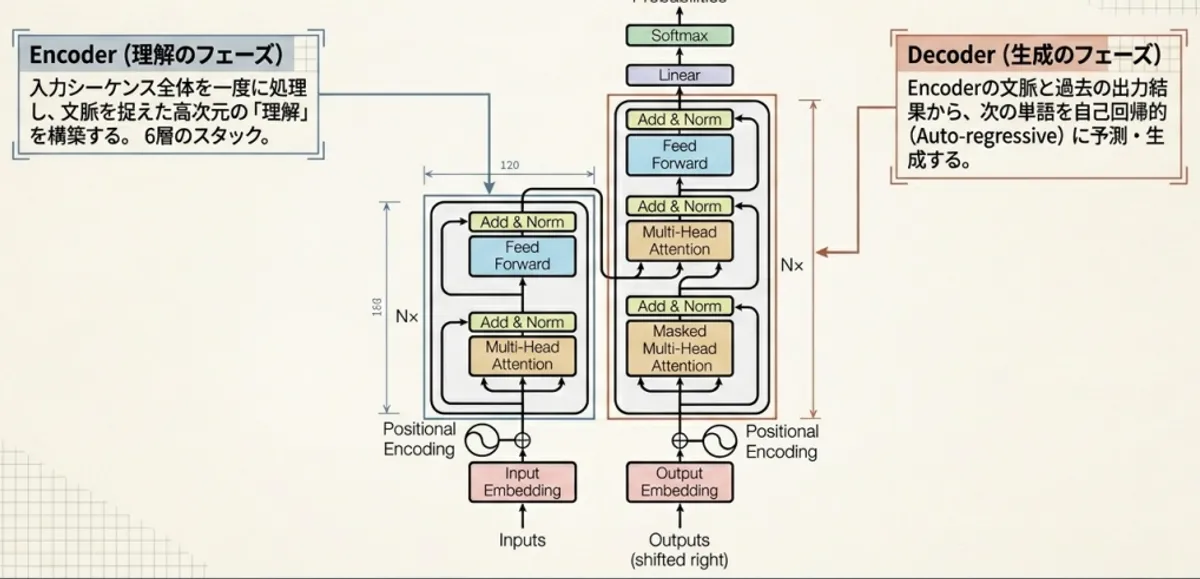
STFT → T×F スペクトログラム ↓Dual-Path(Intra+Interを交互にN回) ↓各ブロックはマカロン構造: ConvSwiGLU(ローカル)→ MH-SA(グローバル)→ ConvSwiGLU(ローカル) ↓複素マスク → ISTFT → 各話者の波形核心技術(Part3)
ConvSwiGLU:SwiGLUのvブランチの線形変換をDepthwise Conv(K=4)に変えただけ。これによりRNNと同等のローカル性を並列に実現。
RMSGroupNorm:D次元をG個のグループに分けてRMSNormを適用。話者情報のグループ独立性を保ちながら効率的に正規化。
実験結果:TF-GridNet(RNNあり, 18.5dB)をTF-Locoformer (M)(RNNなし)が18.8dBで上回ることに成功。
「ローカルな帰納バイアスはアーキテクチャ全体に焼き込まなくても、FFNの中に局所畳み込みを入れるだけで代替できる」
RNNという「時系列専用の構造」を廃止しながら、RNNが担っていた「ローカルな情報の取得」を維持する。
この設計原理はTFドメイン音声分離に限らず、局所構造が重要なあらゆる分野(画像・音楽・医療信号・タンパク質構造予測など)に応用できる汎用的な知見です。
「どこまでをアーキテクチャに担わせ、どこまでをFFNに担わせるか」という設計の問いは、これからのTransformer研究の重要なテーマの一つです。
6. 参考文献
Cornell, S., et al. (2024). TF-Locoformer: Transformer with Local Modeling by Convolution for Time-Frequency Domain Audio Separation. INTERSPEECH 2024. arXiv:2408.03440
Wang, Z., et al. (2023). TF-GridNet: Integrating Full-Band and Sub-Band Modeling for Speech Separation. IEEE/ACM TASLP. arXiv:2211.12433
Shazeer, N. (2020). GLU Variants Improve Transformers. arXiv:2002.05202
Zhang, B., & Sennrich, R. (2019). Root Mean Square Layer Normalization. NeurIPS 2019. arXiv:1910.07467
Wu, Y., & He, K. (2018). Group Normalization. ECCV 2018. arXiv:1803.08494
Luo, Y., & Mesgarani, N. (2019). Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM TASLP. arXiv:1809.07454