
最近、画像処理について勉強してみようと思い、以下の書籍を手に取りました。

『OpenCVによる画像処理入門』という一冊です。 OpenCVの文法だけでなく、画像処理の基礎から応用まで幅広くカバーされており、読み進めるうちに「学んだ理論を実際に動くシステムに反映させたい」という思いが強まりました。 そこで今回は、自動ドアや防犯カメラなど、身近なシーンで活用されている動体検知システムを、画像処理の古典的な手法である背景差分法を用いて実装してみることにしました。
現在、物体検知の分野ではYOLOなどの深層学習を用いるのが主流ですが、あえて画像処理の基礎アルゴリズムに立ち返ることで、画素レベルでの処理の本質を理解することを目指します。 なお、作成したソースコードはこちらのGitHubリポジトリで公開しています。
動体検知の基本コンセプト
動体検知とは、連続する画像や映像の中から変化した領域を特定する技術です。 防犯カメラの不審者検知、自動ドアの開閉制御、交通流の自動計測など、実世界の空間情報をデジタル処理する多くのシステムにおいて、入り口となる重要な役割を担っています。
動体を検知するための最もシンプルかつ直感的な考え方は、過去の映像の状態と比較して、現在の映像に生じた差分を見つけ出すというものです。 この考え方をアルゴリズムとして体系化したのが、今回の主役である背景差分法です。
背景差分法の原理と現実的な課題
背景差分法は、文字通り現在のフレームから物体が存在しない状態の背景を引き算することで、変化した物体のみを抽出する手法です。
原理自体は極めて明快ですが、実環境に適用しようとすると、以下のような特有の課題に直面します。
- 照明環境の変化: 太陽光や雲の通過による明暗の変化を「動き」と誤認してしまう。
- 背景の揺らぎ: 風に揺れる木の葉や水面の輝きなど、本質的でない小さな動きを拾ってしまう。
- 静止物の変化: 長時間置かれた荷物が背景の一部化するような、背景自体の経時変化への対応。
これらの外乱に対してロバスト性を高めるため、一連の処理パイプラインを構築する必要があります。
処理のパイプライン
動体検知プログラムは、カメラから入力される各フレームに対して、以下のステップを順次実行します。
- 映像の入力と前処理: 輝度情報に基づく処理を容易にするため、グレースケール化とノイズ低減を行う。
- 背景モデルの構築: 時間的な平均化を行い、環境変化に適応し続ける「基準」を作成する。
- 差分の計算: 入力フレームと背景モデルの差(絶対値差分)を求める。
- 適応的2値化: 変化量を0か255の2段階に分類し、意味のある候補を浮かび上がらせる。
- 形態学的処理(モルフォロジー演算): ノイズ除去と輪郭の結合を行い、マスク画像を整形する。
- 輪郭抽出: 整形された領域を数学的な座標データ(図形の形)として取り出す。
- フィルタリング: 面積などの閾値に基づき、意味のあるサイズの物体のみを有効な動体として認定する。
- 結果の可視化: 検知した領域をバウンディングボックスで囲み、元の映像にオーバーレイ表示する。
それでは、各ステップの技術的な詳細を追っていきましょう。
1. 映像の入力と前処理
まず、OpenCVを使ってカメラや動画ファイルからフレームを読み込みます。計算コストを最小限に抑えるため、以下の処理を施します。
- グレースケール化 RGBのカラー画像から輝度情報のみを抽出します。3チャンネルの情報を1チャンネルに絞り込むことで、計算負荷を1/3程度まで軽量化できます。
# グレースケール変換gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)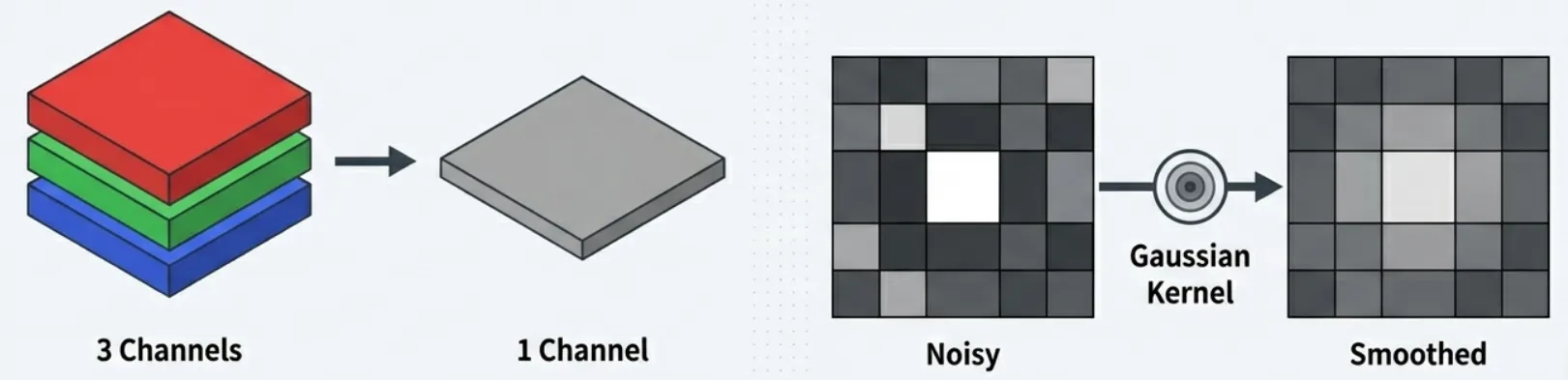
- ガウシアンブラーによる平滑化 カメラセンサー特有のザラつきを抑えるために、ガウス分布に基づくぼかし処理を適用します。 周辺ピクセルと値を馴染ませることで、微小な点ノイズによる誤検知を大幅に低減できます。
# ガウシアンブラーによるノイズ除去gray = cv2.GaussianBlur(gray, (21, 21), 0)この方の資料が参考になったので、載せておきます。
2. 背景モデルの動的構築
背景差分法において、背景をいかに定義・維持するかは非常に重要な課題です。 単に「最初の1枚」を背景として固定すると、雲の影や照明の変化などの環境変化に全く対応できなくなり、すぐに画面全体が「動き」として誤判定されてしまいます。
そこで、移動加重平均 を用いて背景モデルを更新し続けるアプローチを採用します。
- : 時刻 における背景モデル
- : 学習率
- : 現在の入力フレーム
この数式は、新しい情報を少しずつ背景へ混ぜ込むことを意味します。学習率 を適切に設定することで、数秒から数分のスパンでの照明変化には対応しつつ、素早く動く物体は背景に取り込まずに抽出することが可能になります。
# 背景モデルの更新(移動加重平均)# avg は背景モデル、gray は現在のフレーム、alpha は学習率cv2.accumulateWeighted(gray, avg, alpha)bg_model = cv2.convertScaleAbs(avg)3. 差分の計算
動的な背景モデルが完成したら、現在のフレームとの間でピクセルごとの差を求め、その絶対値を生成します。

ここで白く浮かび上がる領域は、背景モデルには存在しない変化したピクセルの候補です。
# 現在のフレームと背景モデルの差分を計算frame_diff = cv2.absdiff(bg_model, gray)4. 2値化と大津の手法
得られた差分画像は濃淡を持つため、どこからが「実際の動き」かを明確にする必要があります。これが2値化処理です。
単一の固定閾値では2値化処理が、ユーザーが入力したパラメータに依存してしまうため、今回は大津の2値化 を活用しました。これは、画像全体のヒストグラムを解析し、背景と前景のクラス間分散が最大となるような「最適な閾値」を自動的に計算するアルゴリズムです。これにより、ユーザーが手動でパラメーターを調整することなく、環境に合わせて最適な「白黒の境界線」を決定できるようになります。
# 大津の手法による自動2値化_, thresh = cv2.threshold(frame_diff, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)大津の二値化処理に関して、この方の記事を参考にさせて頂きました。

5. モルフォロジー演算(形態学的画像処理)
2値化直後の画像には、ノイズや物体の欠損が含まれることが多いため、これを整形します。
- オープニング処理: 小さなノイズを消し去るために収縮した後に膨張を行います。
- クロージング処理: 物体内部の穴を埋めるために膨張した後に収縮を行います。
これらを適切に組み合わせることで、ノイズが少なく物体の輪郭がはっきりとした画像を得ることができます。
# モルフォロジー演算kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))thresh = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel)thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)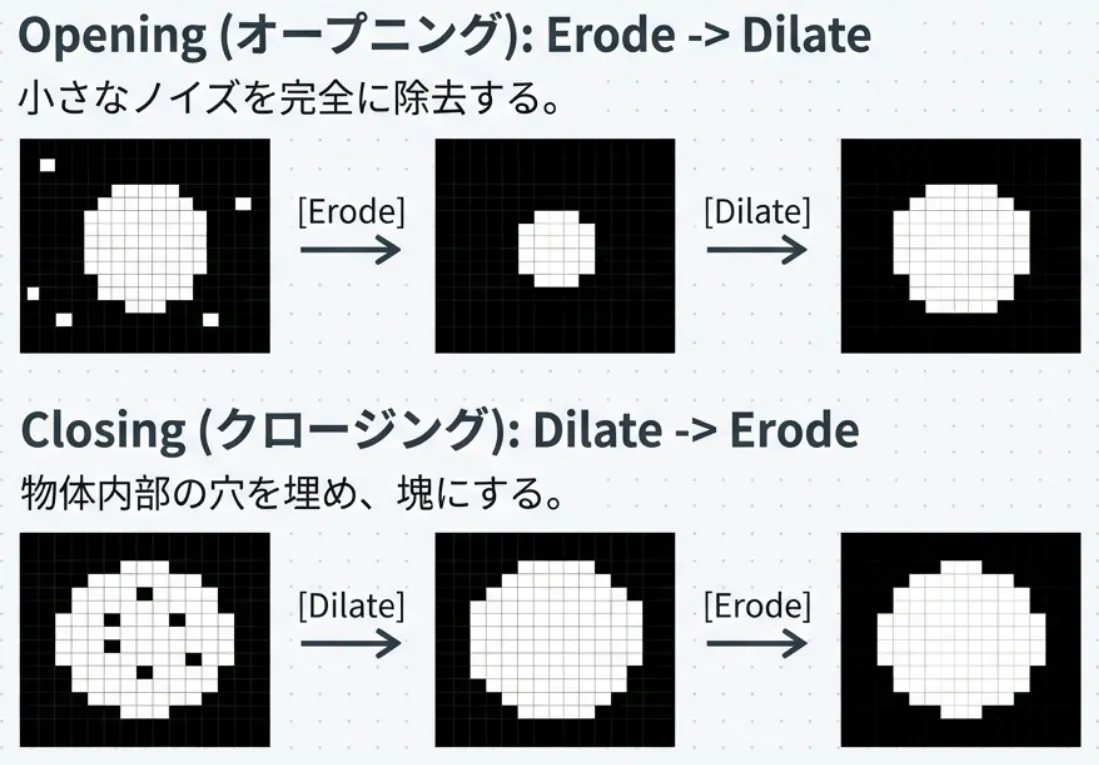
6. 輪郭抽出と図形データの取得
整形されたマスク画像から、各ピクセルの塊を「リスト形式の座標データ」に変換します。これが輪郭抽出 です。
OpenCVの cv2.findContours 関数を用い、cv2.RETR_EXTERNAL(最も外側の境界のみを追跡)や cv2.CHAIN_APPROX_SIMPLE(直線の冗長な点を省略)といったフラグを適切に設定することで、高速かつ正確に物体の形状データを取得できます。
# 輪郭の抽出contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)抽出された輪郭の情報は、次のステップでのフィルタリングや、画面上への可視化に利用されます。
7. 面積フィルタリングと事象判定
抽出したすべての輪郭に対して、面積(包含ピクセル数)を計算します。 「面積が1,000ピクセル以下のものは、カメラの揺れや小さな虫などのノイズとみなして無視する」といったフィルタリングロジックを導入することで、人間や車などの明確な「動体」のみをフィルタリングして取り出すことができます。
for contour in contours: # 面積が閾値より小さい場合は無視 if cv2.contourArea(contour) < 1000: continue
# 動体として認定 (x, y, w, h) = cv2.boundingRect(contour) # ...8. 結果の可視化とUIへの反映
最終的なステップとして、検知した物体の周囲にバウンディングボックス(矩形)を描画します。画像データ cv2.rectangle を用いて、元のカラー映像に情報のレイヤーを重ねることで、システムが何を見ているのかを直感的にユーザーへ伝えます。
# バウンディングボックスの描画cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)実装を振り返って
本記事では、古典的なアルゴリズムである背景差分法を用いた動体検知の全工程を、解説してみました。
実用上の限界として、今回紹介した手法は「固定カメラ」であることが前提条件となります。パン・チルトを行うカメラやドローン映像などの場合には、より高度なグローバルモーション補正やAIベースの検知モデルが必要になります。
画像処理の世界は、数学とプログラミングが視覚的な結果として結びつく非常に面白い分野だと思いました。今後もさらに高度なテーマに挑戦していきたいと思います。