大規模データ向け高速類似文字列検索システムの実装
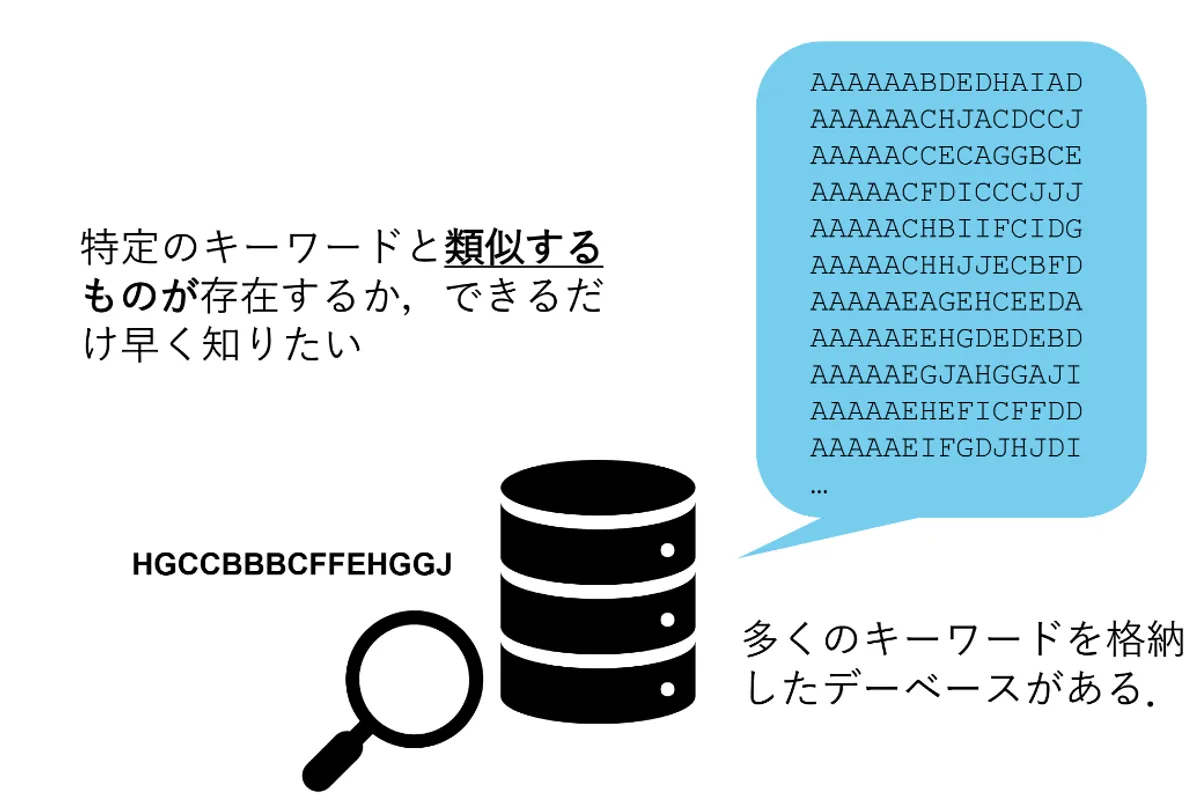
100万件のデータから編集距離3以内の類似文字列を高速検索するシステム。階層的フィルタリングとMyersのビット並列アルゴリズムをC言語で実装し、精度100%と実行速度の最適化を両立。
プロジェクト概要
100万件規模の文字列データベースから、与えられたクエリに対して編集距離3以内の類似文字列を検索するC言語プログラムの開発をしました。計算リソースと実行時間の制約が厳しい中、検索漏れの無い完全な精度を優先事項としつつ、データ構造とハードウェアの特性を活かした高速化アプローチを設計・実装しました。
- 使用言語: C言語, Python(性能評価のみ)
- 開発体制: 5名(アルゴリズムのコア設計を担当)
- 開発期間: 約1ヶ月
- 達成成果: 精度100%を達成(実行時間:18.65秒)
技術的な工夫とアーキテクチャ
本プロジェクトでは、複雑な木構造(BK木など)の導入を見送りました。文字列長に対する許容エラー率が高く(約20%)、木探索によるランダムアクセスがCPUキャッシュのヒット率を低下させ、ボトルネックになると判断したためです。代わりにメモリアクセスの局所性向上と計算コストの低い順に適用する多段階フィルタを採用しました。
1. 鳩の巣原理と計数ソートを用いたO(N)のインデックス構築
15文字の文字列を4つのパート(4,4,4,3文字)に分割し、それぞれを基準にした4種類のインデックスを構築しました。
整数エンコーディング: 対象が10種類の文字種に限定されている点に着目し、各パートを10進数の整数値(0〜9999)に変換。
計数ソートの採用: キーの範囲が狭いことを活かし、比較操作を含まない計算量O(N)の計数ソートでデータを配置。CPUの分岐予測ミスを防ぐとともに、検索時のシーケンシャルアクセス(I/O効率の最大化)を実現しました。
2. 多段階フィルタリングによる高速化パイプライン
検索時、正解以外のデータを出来る限り早期に切り捨てるため、以下の順でフィルタを適用しました。
ヒストグラム間L1距離: 文字種の出現頻度を比較し、差が6を超える候補を除外。これにより全候補の約91.8%を高速に棄却しました。
ハミング距離計算: 64bit XOR演算とハードウェア命令のビットカウントを活用し、置換のみの類似度を定数時間で判定。最終マッチの約25%をここで確定。
Myersのビット並列アルゴリズム: Eugene W. Myersのビット並列アルゴリズムを採用。動的計画法の表計算を論理演算のみに置き換え、条件分岐なしで厳密な編集距離を算出。
評価と分析
開発後、プログラム内部の処理効率を計測・プロファイリングしました。
- ヒストグラムフィルタによってMyers法による高負荷な計算の実行を9割以上スキップできたことが最大の高速化要因でした。
- 一方で、ヒストグラムを通過した候補のうち最終マッチに至ったのは0.26%であり、文字の構成要素は似ているが並び順が異なる偽陽性の削減が、アルゴリズム上の今後の課題であることが浮き彫りになりました。
今後の改善点と考察
アルゴリズム設計の視点
高速化の焦点を候補生成後のフィルタリングに当てすぎたことが反省点です。文字列を4分割ではなく5分割にすることで、鳩ノ巣原理により「少なくとも2か所の完全一致」が保証されることに気が付きました。過剰なフィルタリング処理を実装するよりも、分割数の最適化で検証候補自体を生成させない設計に注力すべきでした。
チーム開発の視点
GitHubを用いた並行開発(ブランチ運用でのプルリクエスト統合)を計画しましたが、タスクの切り出し方が表面にとどまり、特定のメンバーに実装負荷が偏る結果となりました。 技術的な前提知識やデータ構造の設計意図を、コードを書き始める前にチーム全体で深く同期しなかったことが根本的な原因です。この経験から、ツールの運用ルールだけでなく、事前の設計共有やドキュメント化がいかに重要であるかを学びました。